Cette page explique comment utiliser le tableau de bord des insights système pour surveiller aux instances et bases de données Spanner.
À propos des insights système
Le tableau de bord des insights système affiche des tableaux de données et des graphiques concernant une instance ou une base de données sélectionnée, et fournit des mesures des latences, du CPU l'utilisation, le stockage, le débit et d'autres statistiques de performances. Vous pouvez afficher graphiques pour différentes périodes, allant de la dernière heure au au cours des 30 derniers jours.
Le tableau de bord des insights système comprend les sections suivantes (reportez-vous à la capture d'écran):
- Liste des bases de données: affiche les statistiques des bases de données sélectionnées. base de données. Vous pouvez afficher une base de données unique ou un agrégat de toutes les bases de données. Cette option n'est disponible que pour les instances.
- Activation/désactivation de la mise en page:permet de basculer entre une mise en page à une ou deux colonnes.
- Time range filter (Filtre de période) : filtre les statistiques par période, telle que des heures, des jours ou une plage personnalisée.
- Tableaux de données : affiche les statistiques à un moment précis, sur la période sélectionnée.
Graphiques: affiche les graphiques d'utilisation du processeur, de débit, de latence l'utilisation de l'espace de stockage, etc.
Si vous créez une partition (en version preview) dans une liste déroulante supplémentaire permettant d'afficher les graphiques ou un agrégat de toutes les partitions. Vous ne voyez pas ceci liste déroulante si vous n'avez créé aucune partition.
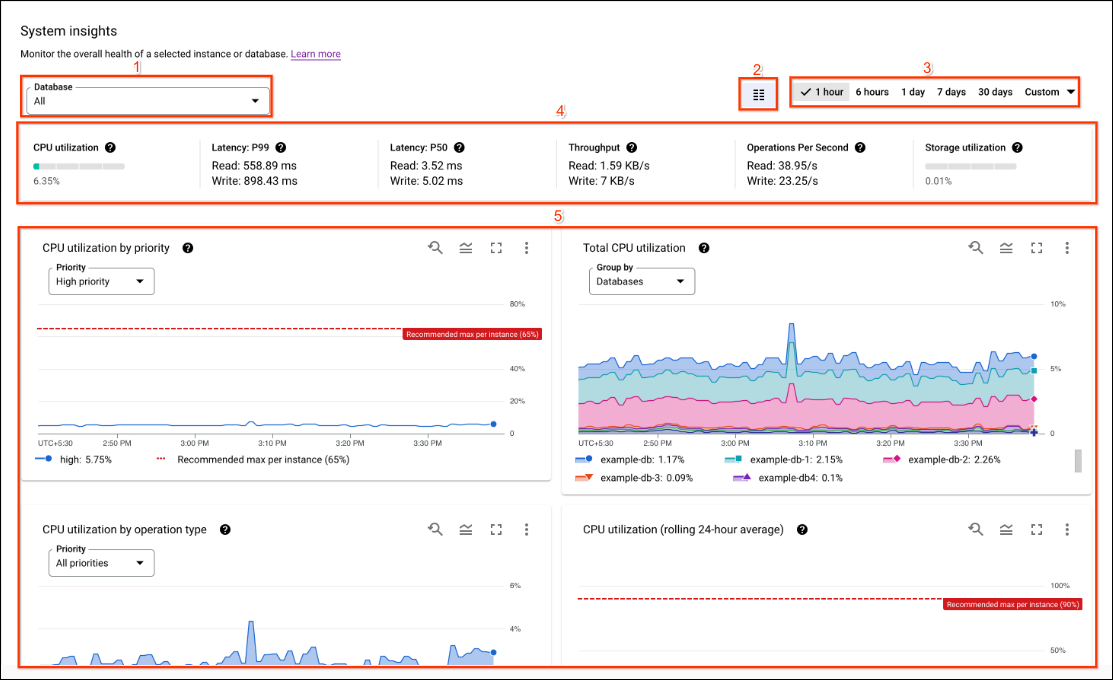
Tableau de données, graphiques et métriques des insights système
Le tableau de bord des insights système fournit les graphiques et métriques suivants pour vous aider l'état actuel et historique d'une instance. La plupart des graphiques et des métriques disponibles au niveau de l'instance. Vous pouvez également afficher de nombreux graphiques et métriques pour une une seule base de données dans une instance.
Tableaux de données disponibles
| Nom | Description |
|---|---|
| Utilisation du processeur | l'utilisation totale du processeur dans une instance la base de données sélectionnée. Dans un emplacement multirégional cette métrique représente la moyenne Utilisation du processeur dans les différentes régions. |
| Latence: P99 | Latence P99 pour les opérations de lecture et d'écriture dans une instance ou une base de données sélectionnée. |
| Latence: P50 | Latence P50 pour les opérations de lecture et d'écriture dans une instance ou une base de données sélectionnée. |
| Débit | Quantité de données non compressées lues ou écrites dans l'instance ou la base de données chaque seconde. Cette valeur se mesure en mégaoctets binaires (Mo), où 1 Mo équivaut à 2^20 octets. Cette unité de mesure est également appelé mébioctet (Mio) |
| Opérations par seconde | Nombre d'opérations par seconde (taux) de en lecture et en écriture dans une instance la base de données sélectionnée. |
| Utilisation du stockage | Au niveau de l'instance, il s'agit du total le pourcentage d'utilisation du stockage Compute Engine. Au niveau de la base de données, l'espace de stockage total utilisé base de données. |
Graphiques et métriques disponibles
Voici un graphique illustrant un exemple de métrique:
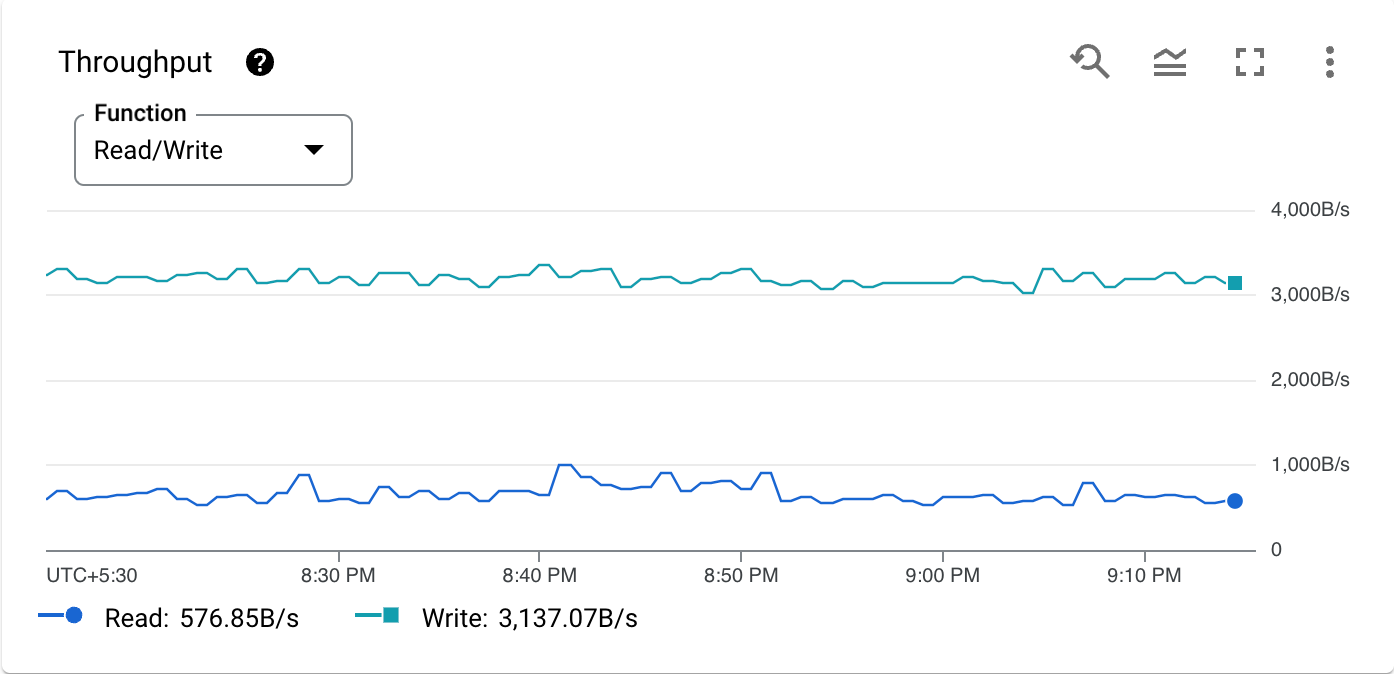
La barre d'outils située sur chaque fiche du graphique fournit l'ensemble suivant options:
Pour zoomer sur une section spécifique d'un graphique, cliquez dessus et faites glisser horizontalement ou verticalement. Pour annuler le zoom, cliquez sur youtube_searched_for Réinitialisez le zoom. Les opérations de zoom s'appliquent à tous les graphiques du tableau de bord en même temps.
Pour masquer ou afficher la légende, cliquez sur legend_toggle Développer/Réduire la légende du graphique
Pour afficher un graphique en mode plein écran, cliquez sur fullscreen Activer/Quitter le mode plein écran Vous pouvez également quitter le mode plein écran en appuyant sur Échap.
Pour afficher d'autres options, cliquez sur more_vert Plus d'options de graphiques.
La plupart des graphiques offrent les options suivantes :
- Télécharger une image PNG
- Téléchargez un fichier CSV.
- Ajouter au tableau de bord personnalisé Cette option vous permet d'ajouter un graphique un nouveau tableau de bord ou un tableau de bord existant dans Cloud Monitoring.
- Afficher dans l'Explorateur de métriques. Afficher la métrique dans Explorateur de métriques : Vous pouvez afficher d'autres métriques Spanner dans l'explorateur de métriques après en sélectionnant le type de ressource Spanner Database.
Le tableau suivant décrit les graphiques qui apparaissent par défaut sur le système
dans le tableau de bord des insights. Le type de métrique de chaque graphique est indiqué. Le type de métrique
suivent ce préfixe: spanner.googleapis.com/. Métrique
d'entraînement
décrit les mesures pouvant être collectées à partir d'une ressource surveillée.
| Nom du graphique et type de métrique |
Description | Disponible pour les instances | Disponible pour les bases de données |
|---|---|---|---|
Utilisation du processeur par priorité instance/cpu/utilization_by_priority |
Pourcentage des ressources CPU de l'instance pour les niveaux élevé, moyen faible, ou toutes les tâches par priorité. Ces tâches incluent les demandes que vous initier des tâches de maintenance que Spanner doit effectuer rapidement. Pour les instances multirégionales, les métriques sont regroupées par région et la priorité. Apprendre en savoir plus sur les tâches à priorité élevée. Apprendre sur l'utilisation du processeur. |
done |
close |
Utilisation totale du processeur instance/cpu/utilization_by_priority |
Nombre total de processeurs utilisation, sous la forme d'un pourcentage des ressources processeur de l'instance ressources. Pour les instances, vous pouvez afficher le graphique empilé de l'utilisation totale du processeur d'utilisation regroupées par base de données ou regroupées par combinaison de tâches le type (Utilisateur/Système) et la priorité. Pour les bases de données, vous pouvez afficher le graphique empilé du CPU total regroupées par type de tâche (utilisateur/système) et leur priorité. Pour les instances multirégionales, vous pouvez choisir la région à afficher ou vous pouvez afficher toutes les régions sous forme de graphiques en courbes. |
done |
done |
Utilisation du processeur par type d'opération instance/cpu/utilization_by_operation_type |
Graphique empilé de l'utilisation du processeur en pourcentage du ressources de processeur de l'instance, regroupées par opérations déclenchées par l'utilisateur comme les lectures, les écritures et les commits. Cette métrique vous permet d'obtenir de l'utilisation du processeur et pour résoudre d'autres problèmes, comme expliqué dans Examiner une utilisation élevée du processeur. Vous pouvez filtrer davantage les tâches par priorité à l'aide des Menu déroulant Priorité. Pour les instances multirégionales, les métriques du graphique en courbes indiquent pourcentage moyen entre les régions. |
done |
done |
Utilisation du processeur (moyenne glissante sur 24 heures) instance/cpu/smoothed_utilization |
Moyenne glissante du nombre total de processeurs Utilisation de Spanner, en pourcentage du processeur de l'instance pour chaque base de données. Chaque point de données est une moyenne des 24 derniers heures. Pour les instances multirégionales, vous pouvez filtrer les métriques dans la ligne graphique par région à l'aide du menu déroulant Région. |
done |
close |
|
Latence par lecture de flux de modifications api/read_request_latencies_by_change_stream |
Distribution des latences des requêtes de lecture par flux de modification. Utiliser ceci d'afficher toutes les latences et de déterminer si une latence est liée à lecture de flux de modification ou lecture de flux sans modification. Les requêtes de flux de modifications prennent du temps et doivent être nombreuses d'une durée de secondes. À l'inverse, les requêtes ne portant pas sur un flux de modifications de courte durée. Cette métrique vous permet d'effectuer les opérations suivantes:
|
close |
done |
Latence api/request_latencies |
Temps nécessaire à Spanner pour gérer une lecture ou une écriture requête. Utilisez le menu déroulant Fonction pour sélectionner Lire ou Écrire, ou sélectionner Lecture/Écriture pour afficher les métriques des deux. Ce la mesure commence lorsque Spanner reçoit une requête et se termine lorsque Spanner commence à envoyer une réponse. Vous pouvez afficher les métriques de latence pour les 50e et 99e centiles à l'aide du menu déroulant Centile: <ph type="x-smartling-placeholder">
|
done |
done |
Latence par base de données api/request_latencies |
Temps nécessaire à Spanner pour gérer une lecture ou une écriture de requête, regroupées par base de données. Utiliser la fonction pour sélectionner Lire ou Écrire, ou sélectionnez Lecture/Écriture pour afficher les métriques des deux. Ce commence lorsque Spanner reçoit une requête et se termine lorsque Spanner commence à envoyer une réponse. Vous pouvez afficher les métriques de latence des 50e et 99e centiles en à l'aide du menu déroulant Centile: <ph type="x-smartling-placeholder">
|
done |
close |
Latence par méthode API api/request_latencies |
Temps nécessaire à Spanner pour traiter une requête, regroupé par les méthodes de l'API Spanner. Cette mesure commence lorsque Spanner reçoit une requête, qui se termine lorsque Spanner commence à envoyer une réponse. Vous pouvez afficher les métriques pour les latences des 50e et 99e centiles à l'aide du menu déroulant Centile: <ph type="x-smartling-placeholder">
|
close |
done |
Latence des transactions api/request_latencies_by_transaction_type |
Temps nécessaire à Spanner pour traiter une transaction. Vous pouvez choisir d'afficher les métriques des types lecture-écriture et lecture seule les transactions. La principale différence entre le graphique de latence et le graphique Le graphique de latence des transactions est le graphique de latence des transactions vous permet de sélectionner l'implication de la variante optimale pour le type en lecture seule. Vous pouvez sélectionner Le responsable est impliqué ou Non la variante optimale est impliquée pour la transaction en lecture seule. Lit cela la latence peut être plus élevée. Vous pouvez utiliser cette graphique pour évaluer si vous devez utiliser des lectures non actualisées sans communiquer avec la variante optimale, en supposant que le code temporel est d'au moins 15 secondes. Pour les transactions en lecture/écriture, le responsable est toujours impliquée dans la transaction. Par conséquent, les données affichées sur le graphique inclut toujours le temps nécessaire pour que la requête et de recevoir une réponse. Vous pouvez afficher les métriques des 50e et 99e centiles latence:
|
done |
done |
Latence des transactions par base de données api/request_latencies_by_transaction_type |
Temps nécessaire à Spanner pour traiter une transaction. Vous pouvez choisir d'afficher les métriques des types lecture-écriture et lecture seule les transactions. La principale différence entre le graphique de latence et le graphique Le graphique "Latence des transactions par base de données" indique que la latence des transactions par base de données vous permet de sélectionner l'implication du leader en lecture seule. Vous pouvez sélectionner Le responsable est impliqué ou Aucune variante optimale n'est impliquée pour la transaction en lecture seule. Les lectures impliquant la variante optimale peuvent connaître une latence plus élevée. Toi vous pouvez utiliser ce graphique pour déterminer si vous devez utiliser des lectures obsolètes avec la variante optimale, en supposant que le code temporel est d'au moins 15 secondes. Pour les transactions en lecture/écriture, le responsable est toujours impliquée dans la transaction. Par conséquent, les données affichées sur le graphique inclut toujours le temps nécessaire pour que la requête et de recevoir une réponse. Vous pouvez afficher les métriques des 50e et 99e centiles latence:
|
done |
close |
Latence des transactions par méthode API api/request_latencies_by_transaction_type |
Temps nécessaire à Spanner pour traiter une transaction. Vous pouvez choisir d'afficher les métriques des types lecture-écriture et lecture seule les transactions. La principale différence entre le graphique de latence et le graphique Le graphique "Latence des transactions par méthode API" indique que le graphique Le graphique de latence par méthode API vous permet de sélectionner la variante optimale pour le type en lecture seule. Vous pouvez sélectionner Le leader est impliqués ou aucun leader n'est impliqué pour la en lecture seule. Les lectures impliquant le leader pourraient connaissent une latence plus élevée. Vous pouvez utiliser ce graphique pour évaluer si vous doit utiliser des lectures non actualisées sans communiquer avec le responsable, en supposant que le code temporel est d'au moins 15 secondes. Pour les transactions en lecture/écriture, le la variante optimale est toujours impliquée dans la transaction. Par conséquent, les données affichées sur la le graphique inclut toujours le temps nécessaire pour que la requête atteigne et de recevoir une réponse. Vous pouvez afficher les métriques de latence des 50e et 99e centiles:
|
close |
done |
Opérations par seconde api/api_request_count |
Nombre d'opérations (lecture/écriture) effectuées par Spanner seconde ou le nombre d'erreurs survenues sur la serveur par seconde. Vous pouvez choisir les opérations à afficher dans ce graphique:
|
done |
done |
Opérations par seconde par base de données api/api_request_count |
Nombre d'opérations (lecture/écriture) effectuées par Spanner seconde ou le nombre d'erreurs survenues sur la serveur par seconde. Ce graphique est regroupé par base de données. Vous pouvez choisir les opérations à afficher dans ce graphique:
|
done |
close |
Opérations par seconde par méthode API api/api_request_count |
Nombre d'opérations effectuées par Spanner Deuxièmement, regroupées par méthode API Spanner |
close |
done |
Débit api/sent_bytes_count (lire) api/received_bytes_count (écriture) |
Quantité de données non compressées lues ou écrites vers l'instance ou la base de données chaque seconde. Cette valeur se mesure en unités d'octets binaires. Cette unité de mesure est basée sur alimentation sur 2. Par exemple, 1 gigaoctet binaire (Go) équivaut à 2^30 octets. Cette unité de mesure est également appelée gibioctet (Gio). Le débit en lecture inclut les requêtes et les réponses des méthodes la lecture Google Cloud et pour les requêtes SQL. Il inclut également les requêtes et les réponses pour les instructions LMD. Le débit en écriture inclut les requêtes et les réponses pour valider les données via la mutation API. Il exclut les requêtes et les réponses pour les instructions LMD. |
done |
done |
Débit par base de données api/sent_bytes_count (lire) api/received_bytes_count (écriture) |
Quantité de données non compressées lues ou écrites vers l'instance ou la base de données, regroupées par base de données. Cette valeur est mesurée en unités d'octets binaires. Cette unité de mesure est basée sur alimentation sur 2. Par exemple, 1 gigaoctet binaire (Go) équivaut à 2^30 octets. Cette unité de mesure est également appelée gibioctet (Gio). Le débit en lecture inclut les requêtes et les réponses des méthodes la lecture Google Cloud et pour les requêtes SQL. Il inclut également les requêtes et les réponses pour les instructions LMD. Le débit en écriture inclut les requêtes et les réponses pour valider les données via la mutation API. Il exclut les requêtes et les réponses pour les instructions LMD. |
done |
close |
Débit par méthode API api/sent_bytes_count (lecture) api/received_bytes_count (écriture) |
Quantité de données non compressées lues ou écrites vers l'instance ou la base de données, regroupées par méthode API. Cette valeur se mesure en unités d'octets binaires. Cette unité de mesure est basée sur alimentation sur 2. Par exemple, 1 gigaoctet binaire (Go) équivaut à 2^30 octets. Cette unité de mesure est également appelée gibioctet (Gio). Le débit en lecture inclut les requêtes et les réponses des méthodes la lecture Google Cloud et pour les requêtes SQL. Il inclut également les requêtes et les réponses pour les instructions LMD. Le débit en écriture inclut les requêtes et les réponses pour valider les données via la mutation API. Il exclut les requêtes et les réponses pour les instructions LMD. |
close |
done |
Espace de stockage total instance/storage/used_bytes |
Quantité de données stockée dans l'instance ou la base de données. Cette valeur est mesurée en octets binaires. Exemple : 1 le gigaoctet binaire (Go) est de 2^30 octets. Cette unité de mesure est également appelé gibioctet, (Gio). |
done |
done |
Espace de stockage total par base de données instance/storage/used_bytes |
La quantité de données stockées dans l'instance ou la base de données, regroupées par base de données. Cette valeur est mesurée en octets binaires. Exemple : 1 le gigaoctet binaire (Go) est de 2^30 octets. Cette unité de mesure est également appelé gibioctet, (Gio). |
done |
close |
Espace de stockage de base de données par table (aucune) |
Quantité de données stockées dans l'instance ou la base de données, regroupées par tables dans la base de données sélectionnée. Cette valeur est mesurée en octets binaires. Exemple : 1 le gigaoctet binaire (Go) est de 2^30 octets. Cette unité de mesure est également appelé gibioctet, (Gio). Ce graphique obtient ses données en interrogeant SPANNER_SYS.TABLE_SIZES_STATS_1HOUR Pour en savoir plus, consultez
<ph type="x-smartling-placeholder"></ph>
Statistiques sur les tailles des tables. |
close |
done |
Tables les plus utilisées par les opérations (aucune) |
Les 15 tables et index les plus utilisés dans l'instance ou la base de données, déterminés par le le nombre d'opérations de lecture, d'écriture ou de suppression. Ce graphique obtient ses données en interrogeant les tables de statistiques des opérations de la table. Pour en savoir plus, consultez <ph type="x-smartling-placeholder"></ph> Statistiques des opérations de la table. |
close |
done |
Tables les moins utilisées par les opérations (aucune) |
Les 15 tables et index les moins utilisés dans l'instance ou la base de données, déterminés par le le nombre d'opérations de lecture, d'écriture ou de suppression. Ce graphique obtient ses données en interrogeant les tables de statistiques des opérations de la table. Pour en savoir plus, consultez <ph type="x-smartling-placeholder"></ph> Statistiques des opérations de la table. |
close |
done |
Temps d'attente pour le verrouillage lock_stat/total/lock_wait_time |
Le temps d'attente de verrouillage pour une transaction est le temps nécessaire pour acquérir un sur une ressource détenue par une autre transaction. Temps total d'attente pour le verrouillage les conflits sont enregistrés pour l'ensemble de la base de données. |
done |
done |
Temps d'attente pour le verrouillage par base de données lock_stat/total/lock_wait_time |
Le temps d'attente de verrouillage pour une transaction est le temps nécessaire pour acquérir un sur une ressource détenue par une autre transaction. Temps total d'attente pour le verrouillage les conflits sont enregistrés pour l'ensemble de la base de données. |
done |
close |
Espace de stockage total pour la sauvegarde instance/backup/used_bytes |
La quantité de données stockées dans les sauvegardes associées à l'instance ou à la base de données. Cette valeur se mesure en unités d'octets binaires. Par exemple, 1 gigaoctet binaire (Go) correspond à 2^30 octets. Cette unité de mesure est parfois appelée gibioctet. (Gio). |
done |
done |
Espace de stockage total de la sauvegarde par base de données instance/backup/used_bytes |
La quantité de données stockées dans les sauvegardes associées à une instance ou une base de données, regroupés par base de données. Cette valeur se mesure en unités d'octets binaires. Par exemple, 1 gigaoctet binaire (Go) correspond à 2^30 octets. Cette unité de mesure est parfois appelée gibioctet. (Gio). |
done |
close |
Capacité de calcul instance/processing_units instance/nœuds |
Le calcul la capacité est le nombre d'unités de traitement ou de nœuds disponibles une instance. Vous pouvez choisir d'afficher la capacité en cours de traitement unités ou en nœuds. |
done |
close |
Répartition des variantes optimales instance/leader_percentage_by_region |
Pour les instances multirégionales, vous pouvez afficher le nombre de bases de données avec le paramètre majorité des dirigeants (>= 50%) dans une région donnée. Dans la section Régions, si vous sélectionnez une région spécifique le graphique indique le nombre total de bases de données dont la région sélectionnée est la région principale. Si vous sélectionnez Toutes les régions sous le menu déroulant Régions, le graphique affiche une ligne pour chaque région, et chaque ligne indique le nombre total de bases de données dans ayant cette région comme région principale. Pour les bases de données d'une instance multirégionale, vous pouvez afficher le pourcentage de leaders regroupées par région. Par exemple, si une base de données comporte cinq variantes optimales, une dans la région us-west1. et quatre dans la région us-east1, Le graphique comporte deux lignes (un par région). Une ligne pour us-west1 est à 20%, et l'autre pour us-west1 us-east1 est à 80%. Le graphique us-west1 montre une seule ligne à 20%, et le Le graphique us-east1 affiche une seule ligne à 80%. Notez que si une base de données a été créée récemment ou qu'une région principale a été modifiée récemment, il est possible que les graphiques ne se stabilisent pas correctement à distance. Ce graphique n'est disponible que pour les instances multirégionales. |
done |
done |
|
Disponibilité du quorum birégional instance/dual_region_quorum_availability |
Ce graphique n'est disponible que pour configurations d'instances birégionales. Elle montre une chronologie de l'état de trois quorums: la birégionale le quorum et le quorum d'une région unique dans chaque région. Le graphique comporte un menu déroulant "Disponibilité du quorum" sont en mode Opérationnel ou Interruption. Utiliser ceci avec les métriques de taux d'erreur et de latence, pour vous aider décisions autogérées au moment du basculement en cas d'événements régionaux d'échecs. Pour en savoir plus, consultez Basculement et restauration automatique. Pour procéder au basculement et à la restauration automatique manuellement, consultez la page Modifier le quorum birégional |
done |
close |
|
Nombre d'appels à un service distant query_stat/total/remote_service_calls_count |
Nombre d'appels à un service distant, regroupés par service et par code de réponse. Répond par un code de réponse HTTP, tel que 200 ou 500. |
done |
done |
|
Latences des appels à un service distant query_stat/total/remote_service_calls_latencies |
Latence des appels à un service distant, regroupée par service. Vous pouvez afficher les métriques de latence pour les latences des 50e et 99e centiles à l'aide du menu déroulant Centile:
|
done |
done |
|
Nombre de lignes traitées par un service distant query_stat/total/remote_service_processed_rows_count |
Nombre de lignes traitées par un service distant, regroupées par servicer et par code de réponse. Répond par un code de réponse HTTP, tel que 200 ou 500. |
done |
done |
|
Latences des lignes d'un service distant query_stat/total/remote_service_processed_rows_latencies |
Nombre de lignes traitées par un service distant, regroupées par service et par code de réponse. Vous pouvez afficher les métriques de latence pour les latences des 50e et 99e centiles à l'aide du menu déroulant Centile:
|
done |
done |
|
Octets réseau du service distant query_stat/total/remote_service_network_bytes_sizes |
Octets réseau échangés avec le service distant, regroupés par service et par direction. Cette valeur est mesurée en octets binaires. Cette unité de les mesures sont basées sur <ph type="x-smartling-placeholder"></ph> puissance 2. Par exemple, 1 gigaoctet binaire (Go) équivaut à 2^30 octets. Cette unité des mesures est également appelée gibioctet (Gio) : La direction fait référence au trafic envoyé ou reçu. Vous pouvez afficher les métriques pour les 50e et 99e centiles des échanges d'octets réseau à l'aide de la liste déroulante "Centile" :
|
done |
done |
Graphiques et métriques de l'autoscaler géré
En plus des options présentées dans la section précédente, lorsqu'une instance géré par l'autoscaler est activé, le graphique de capacité de calcul Bouton Afficher les journaux Lorsque vous cliquez sur ce bouton, les journaux du d'un autoscaler géré.
Les métriques suivantes sont disponibles pour les instances dont le niveau d'accès est géré Autoscaler activé.
| Nom du graphique et type de métrique | Description |
|---|---|
| Capacité de calcul | Avec des nœuds sélectionnés. |
|
instance/autoscaling/min_node_count |
Nombre minimal de nœuds que l'autoscaler est configuré pour allouer au Compute Engine. |
|
instance/autoscaling/max_node_count |
Le nombre maximal de nœuds que l'autoscaler est configuré pour allouer au Compute Engine. |
|
instance/autoscaling/recommended_node_count_for_cpu |
Nombre de nœuds recommandé en fonction de l'utilisation du processeur par le Compute Engine. |
|
instance/autoscaling/recommended_node_count_for_storage |
Nombre de nœuds recommandé en fonction de l'utilisation du stockage de l'instance. |
| Capacité de calcul | Avec des unités de traitement sélectionnées. |
|
instance/autoscaling/min_processing_units |
Nombre minimal d'unités de traitement que l'autoscaler est configuré pour allouer à l'instance. |
|
instance/autoscaling/max_processing_units |
Nombre maximal d'unités de traitement que l'autoscaler est configuré à allouer à l'instance. |
|
instance/autoscaling/recommended_processing_units_for_cpu |
Nombre recommandé d'unités de traitement. Cette recommandation est basée sur l'utilisation précédente du processeur par l'instance. |
|
instance/autoscaling/recommended_processing_units_for_storage |
Nombre recommandé d'unités de traitement à utiliser. Cette recommandation est en fonction de l'utilisation précédente du stockage de l'instance. |
| Utilisation du processeur par priorité | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
Objectif d'utilisation du processeur de haute priorité à utiliser pour l'autoscaling. |
| Espace de stockage total | Avec des unités de traitement sélectionnées. |
|
instance/storage/limit_bytes |
Limite de stockage de l'instance en octets |
|
instance/autoscaling/storage_utilization_target |
Objectif d'utilisation du stockage à utiliser pour l'autoscaling. |
Conservation des données
La durée maximale de conservation des données pour la plupart des métriques du tableau de bord des insights système est de six semaines. Toutefois, pour le graphique Database storage by table (Stockage de la base de données par table), les données sont consommée à partir du SPANNER_SYS.TABLE_SIZES_STATS_1HOUR (au lieu de Spanner), qui a une durée de conservation maximale de 30 jours. Voir Conservation des données pour en savoir plus.
Afficher le tableau de bord des insights système
Pour afficher la page "Insights sur le système", vous devez disposer des éléments suivants : Identity and Access Management (IAM) en plus des autorisations Spanner les autorisations Autorisations Spanner au niveau de l'instance et de la base de données:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Pour en savoir plus sur les rôles IAM de Spanner consultez la page Contrôle des accès avec IAM.
Si vous activez l'autoscaler géré sur votre
une instance, vous devez également disposer de l'autorisation logging.logEntries.list pour afficher
les journaux de l'autoscaler géré.
Pour en savoir plus sur cette autorisation, consultez Rôles prédéfinis :
Pour afficher le tableau de bord des insights système, procédez comme suit:
Dans la console Google Cloud, ouvrez la liste des instances Spanner.
Effectuez l'une des opérations suivantes :
Pour afficher les métriques d'une instance, cliquez sur le nom de l'instance que vous souhaitez découvrir, puis cliquez sur Insights sur le système dans le menu de navigation.
Pour afficher les métriques d'une base de données, cliquez sur le nom de l'instance, sélectionnez une base de données, puis cliquez sur Insights sur le système dans le menu de navigation.
Facultatif: Pour afficher les données historiques d'une autre période, recherchez la en haut à droite de la page, puis cliquez sur la période pour les afficher.
Facultatif : Pour contrôler les données affichées, cliquez sur l'une des listes déroulantes du graphique. Par exemple, si l'instance utilise une configuration multirégionale, certains graphiques fournissent une liste déroulante permettant d'afficher les données d'une région spécifique. Les graphiques ne fournissent pas tous de listes déroulantes.
Étape suivante
- Comprendre l'utilisation du processeur et la latence pour Spanner.
- Configurez des graphiques et des alertes personnalisés avec Surveillance.
- Obtenez des informations sur les types d'instances Spanner.