이 페이지에서는 Spanner 데이터베이스 이외의 데이터베이스에서 내보낸 Avro 파일을 준비하여 Spanner로 가져오는 방법을 설명합니다. 이전에 내보낸 Spanner 데이터베이스를 가져오려면 Spanner Avro 파일 가져오기를 확인하세요.
이 프로세스는 Dataflow를 사용하여 각 테이블을 채우는 대상 테이블과 Avro 파일을 지정하는 Avro 파일 및 JSON 매니페스트 파일 집합을 포함하는 Cloud Storage 버킷에서 데이터를 가져옵니다.
시작하기 전에
Spanner 데이터베이스를 가져오려면 먼저 Spanner, Cloud Storage, Compute Engine, Dataflow API를 사용 설정해야 합니다.
또한 충분한 할당량과 필수 IAM 권한이 필요합니다.
할당량 요구사항
가져오기 작업의 할당량 요구사항은 다음과 같습니다.
- Spanner: 가져올 데이터 양을 지원할 수 있는 충분한 컴퓨팅 용량이 있어야 합니다. 데이터베이스를 가져오는 데 추가 컴퓨팅 용량이 필요하지는 않지만 적당한 시간 안에 작업을 마치려면 컴퓨팅 용량을 추가해야 할 수도 있습니다. 자세한 내용은 작업 최적화를 참조하세요.
- Cloud Storage: 가져오려면 이전에 내보낸 파일이 포함된 버킷이 있어야 합니다. 버킷의 크기를 설정할 필요는 없습니다.
- Dataflow: 가져오기 작업에는 다른 Dataflow 작업과 동일한 CPU, 디스크 사용량, IP 주소 Compute Engine 할당량이 적용됩니다.
Compute Engine: 가져오기 작업을 실행하기 전에 Dataflow가 사용하는 Computer Engine에 초기 할당량을 설정해야 합니다. 이 할당량은 Dataflow가 작업에 사용할 수 있는 최대 리소스 수를 나타냅니다. 권장되는 시작 값은 다음과 같습니다.
- CPU: 200
- 사용 중인 IP 주소: 200
- 표준 영구 디스크: 50TB
일반적으로 다른 조정은 할 필요가 없습니다. Dataflow는 자동 확장을 제공하므로 가져오기 중에 사용된 실제 리소스에 대해서만 비용을 지불하면 됩니다. 작업에 더 많은 리소스가 사용될 수 있으면 Dataflow UI에 경고 아이콘이 표시됩니다. 경고 아이콘이 표시되더라도 작업은 완료됩니다.
IAM 요구사항
데이터베이스를 가져오려면 가져오기 작업과 관련된 모든 서비스를 사용할 수 있는 충분한 권한이 있는 IAM 역할도 있어야 합니다. 역할과 권한을 부여하는 방법은 IAM 역할 적용을 참조하세요.
데이터베이스를 가져오는 데 필요한 역할은 다음과 같습니다.
- Google Cloud 프로젝트 수준:
- Spanner 뷰어(
roles/spanner.viewer) - Dataflow 관리자(
roles/dataflow.admin) - 스토리지 관리자(
roles/storage.admin)
- Spanner 뷰어(
- Spanner 데이터베이스나 인스턴스 수준 또는 Google Cloud 프로젝트 수준:
- Spanner 데이터베이스 리더(
roles/spanner.databaseReader) - Spanner 데이터베이스 관리자(
roles/spanner.databaseAdmin)
- Spanner 데이터베이스 리더(
비 Spanner 데이터베이스에서 Avro 파일로 데이터 내보내기
가져오기 프로세스는 Cloud Storage 버킷에 있는 Avro 파일에서 데이터를 가져옵니다. 모든 소스에서 Avro 형식으로 데이터를 내보낼 수 있고 가능한 모든 방법을 사용할 수 있습니다.
데이터를 비 Spanner 데이터베이스에서 Avro 파일로 내보내려면 다음 단계를 수행합니다.
데이터를 내보낼 때는 다음 사항에 유의하세요.
- 모든 Avro 기본 유형 및 배열 복합 유형을 사용하여 내보낼 수 있습니다.
Avro 파일의 각 행에서 다음 행 유형 중 하나를 사용해야 합니다.
ARRAYBOOLBYTES*DOUBLEFLOATINTLONG†STRING‡
*
BYTES유형의 열은 SpannerNUMERIC을 가져오는 데 사용됩니다. 자세한 내용은 아래의 권장 매핑을 참조하세요.†,‡ 타임스탬프를 저장하는
LONG또는 타임스탬프를 SpannerTIMESTAMP로 저장하는STRING을 가져올 수 있습니다. 자세한 내용은 아래의 권장 매핑을 참조하세요.Avro 파일을 내보낼 때 메타데이터를 포함하거나 생성할 필요는 없습니다.
파일에 특정 이름 지정 규칙을 따를 필요는 없습니다.
파일을 Cloud Storage로 직접 내보내지 않는 경우, Cloud Storage 버킷에 Avro 파일을 업로드해야 합니다. 자세한 안내는 Cloud Storage에 객체 업로드를 참조하세요.
비 Spanner 데이터베이스에서 Spanner로 Avro 파일 가져오기
Avro 파일을 비 Spanner 데이터베이스 데이터베이스에서 Spanner로 가져오려면 다음 단계를 수행합니다.
- 대상 테이블을 만들고 Spanner 데이터베이스의 스키마를 정의합니다.
- Cloud Storage 버킷에
spanner-export.json파일을 만듭니다. - gcloud CLI를 사용하여 Dataflow 가져오기 작업을 실행합니다.
1단계: Spanner 데이터베이스의 스키마 만들기
가져오기를 실행하기 전에 Spanner에서 대상 테이블을 만들고 스키마를 정의해야 합니다.
Avro 파일의 각 열에 적절한 열 유형을 사용하는 스키마를 만들어야 합니다.
권장 매핑
GoogleSQL
| Avro 열 유형 | Spanner 열 유형 |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOL |
BYTES |
|
DOUBLE |
FLOAT64 |
FLOAT |
FLOAT64 |
INT |
INT64 |
LONG |
|
STRING |
|
PostgreSQL
| Avro 열 유형 | Spanner 열 유형 |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOLEAN |
BYTES |
|
DOUBLE |
DOUBLE PRECISION |
FLOAT |
DOUBLE PRECISION |
INT |
BIGINT |
LONG |
|
STRING |
|
2단계: spanner-export.json 파일 만들기
또한 Cloud Storage 버킷에 spanner-export.json이라는 이름의 파일을 만들어야 합니다. 이 파일은 데이터베이스 언어를 지정하고 각 테이블의 이름과 데이터 파일 위치를 나열하는 tables 배열을 포함합니다.
파일 콘텐츠의 형식은 다음과 같습니다.
{
"tables": [
{
"name": "TABLE1",
"dataFiles": [
"RELATIVE/PATH/TO/TABLE1_FILE1",
"RELATIVE/PATH/TO/TABLE1_FILE2"
]
},
{
"name": "TABLE2",
"dataFiles": ["RELATIVE/PATH/TO/TABLE2_FILE1"]
}
],
"dialect":"DATABASE_DIALECT"
}
여기서 DATABASE_DIALECT = {GOOGLE_STANDARD_SQL | POSTGRESQL}입니다.
언어 요소를 생략하면 기본적으로 언어가 GOOGLE_STANDARD_SQL로 설정됩니다.
3단계: gcloud CLI를 사용하여 Dataflow 가져오기 작업 실행
가져오기 작업을 시작하려면 Google Cloud CLI 사용 안내에 따라 Avro to Spanner 템플릿을 사용하여 작업을 실행합니다.
가져오기 작업을 시작한 후에는 Google Cloud 콘솔에서 작업에 대한 세부정보를 확인할 수 있습니다.
가져오기 작업이 완료된 후에 필요한 보조 색인과 외환 키를 추가합니다.
가져오기 작업 리전 선택
Cloud Storage 버킷 위치에 따라 다른 리전을 선택할 수 있습니다. 아웃바운드 데이터 전송 요금이 부과되지 않도록 하려면 Cloud Storage 버킷 위치와 일치하는 리전을 선택합니다.
Cloud Storage 버킷 위치가 리전인 경우 리전을 사용할 수 있으면 가져오기 작업에 동일한 리전을 선택하여 무료 네트워크 사용량을 활용할 수 있습니다.
Cloud Storage 버킷 위치가 이중 리전인 경우 리전 중 하나를 사용할 수 있으면 가져오기 작업에 이중 리전을 구성하는 두 리전 중 하나를 선택하여 무료 네트워크 사용량을 활용할 수 있습니다.
같은 위치에 있는 리전을 가져오기 작업에 사용할 수 없거나 Cloud Storage 버킷 위치가 멀티 리전이면 아웃바운드 데이터 전송 요금이 청구됩니다. Cloud Storage 데이터 전송 가격 책정을 참조하여 데이터 전송 요금이 가장 적은 리전을 선택하세요.
Dataflow UI에서 작업 보기 또는 문제 해결
가져오기 작업을 시작한 후에는 Google Cloud 콘솔의 Dataflow 섹션에 로그를 포함한 작업의 세부정보가 표시됩니다.
Dataflow 작업 세부정보 보기
현재 실행 중인 작업을 포함하여 지난주에 실행한 가져오기/내보내기 작업의 세부정보를 확인하려면 다음을 실행합니다.
- 데이터베이스의 데이터베이스 개요 페이지로 이동합니다.
- 왼쪽 창에서 가져오기/내보내기 메뉴 항목을 클릭합니다. 데이터베이스의 가져오기/내보내기 페이지에 최근 작업 목록이 표시됩니다.
데이터베이스의 가져오기/내보내기 페이지에서 Dataflow 작업 이름 열에 있는 작업 이름을 클릭합니다.
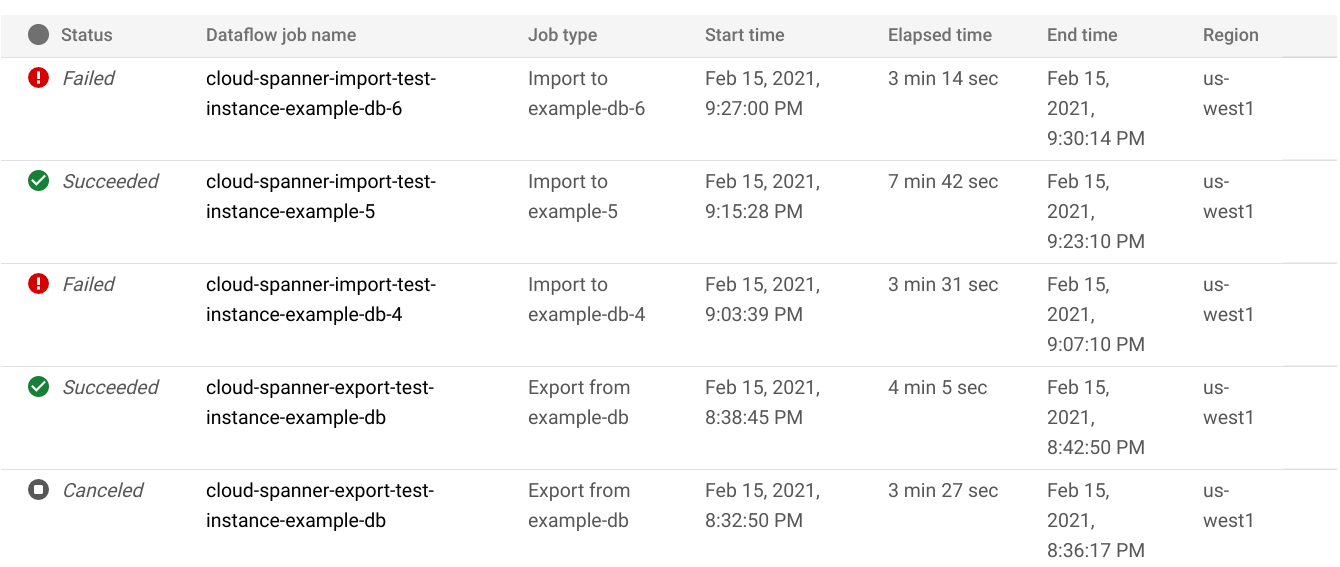
Google Cloud 콘솔에 Dataflow 작업의 세부정보가 표시됩니다.
일주일 이상 전에 실행한 작업을 보려면 다음을 수행합니다.
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
목록에서 작업을 찾은 다음 작업 이름을 클릭합니다.
Google Cloud 콘솔에 Dataflow 작업의 세부정보가 표시됩니다.
작업의 Dataflow 로그 보기
Dataflow 작업의 로그를 보려면 위에서 설명한대로 작업의 세부정보 페이지로 이동한 다음 작업 이름 오른쪽에 있는 로그를 클릭합니다.
작업이 실패한 경우 로그에서 오류를 찾습니다. 오류가 있으면 오류 개수가 로그 옆에 표시됩니다.

작업 오류를 보려면 다음을 수행합니다.
로그 옆에 있는 오류 개수를 클릭합니다.
Google Cloud 콘솔에 작업 로그가 표시됩니다. 오류를 보려면 스크롤해야 할 수도 있습니다.
오류 아이콘(
 )이 있는 항목을 찾습니다.
)이 있는 항목을 찾습니다.개별 로그 항목을 클릭하여 내용을 펼칩니다.
Dataflow 작업 문제 해결에 대한 자세한 내용은 파이프라인 문제 해결을 참조하세요.
실패한 가져오기 작업 문제 해결
작업 로그에 다음 오류가 표시되는 경우가 있습니다.
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Google Cloud 콘솔에 있는 Spanner 데이터베이스의 모니터링 탭에서 99% 읽기/쓰기 지연 시간을 확인합니다. 높은 값(수 초)이 표시되면 인스턴스가 과부하되어 쓰기 제한 시간이 초과되고 실패했음을 나타냅니다.
지연 시간이 긴 이유 중 하나는 Dataflow 작업에서 너무 많은 작업자를 통해 실행되어 Spanner 인스턴스에 너무 많은 부하가 발생하기 때문입니다.
Google Cloud 콘솔에서 Spanner 데이터베이스의 인스턴스 세부정보 페이지에 있는 가져오기/내보내기 탭을 사용하는 대신 Dataflow 작업자 수를 제한하려면 Dataflow Cloud Storage Avro to Cloud Spanner 템플릿을 사용하여 가져오기를 시작하고 다음 설명대로 최대 작업자 수를 지정해야 합니다Dataflow Console을 사용할 경우 최대 작업자 매개변수는 템플릿에서 작업 만들기 페이지의 선택적 매개변수 섹션에 있습니다.
gcloud를 사용할 경우
max-workers인수를 지정합니다. 예를 들면 다음과 같습니다.gcloud dataflow jobs run my-import-job \ --gcs-location='gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner' \ --region=us-central1 \ --parameters='instanceId=test-instance,databaseId=example-db,inputDir=gs://my-gcs-bucket' \ --max-workers=10
느리게 실행되는 가져오기 작업 최적화
초기 설정의 제안에 따랐다면 일반적으로 다른 조정이 필요 없습니다. 작업이 느리게 실행되는 경우에는 몇 가지 다른 최적화 방법을 시도할 수 있습니다.
작업 및 데이터 위치 최적화: Spanner 인스턴스와 Cloud Storage 버킷이 있는 리전과 동일한 리전에서 Dataflow 작업을 실행합니다.
충분한 Dataflow 리소스 확보: 관련 Compute Engine 할당량에 따라 Dataflow 작업의 리소스가 제한되는 경우에는 Google Cloud 콘솔에서 작업의 Dataflow 페이지에 경고 아이콘(
 )과 로그 메시지가 표시됩니다.
)과 로그 메시지가 표시됩니다.
이 경우 CPU, 사용 중인 IP 주소, 표준 영구 디스크의 할당량을 늘리면 작업 실행 시간이 단축될 수 있지만 Compute Engine 요금이 늘어날 수 있습니다.
Spanner CPU 사용률 확인: 인스턴스의 CPU 사용률이 65%를 초과하면 인스턴스의 컴퓨팅 용량을 늘리면 됩니다. 용량을 추가하면 Spanner 리소스가 늘어나고 작업 속도가 빨라지지만 Spanner 요금이 더 많이 청구됩니다.
가져오기 작업 성능에 영향을 미치는 요소
가져오기 작업 완료에 걸리는 시간은 몇 가지 요소의 영향을 받습니다.
Spanner 데이터베이스 크기: 처리하는 데이터가 많을수록 시간과 리소스가 더 많이 소요됩니다.
다음을 포함한 Spanner 데이터베이스 스키마:
- 테이블 수
- 행 크기
- 보조 색인 수
- 외래 키 수
- 변경 내역 수
데이터 위치: 데이터는 Dataflow를 사용하여 Spanner와 Cloud Storage 간에 전송됩니다. 이 세 가지 구성요소가 같은 리전에 위치하는 것이 이상적입니다. 구성요소가 서로 다른 리전에 있으면 다른 리전으로 데이터를 이동하느라 작업 속도가 느려집니다.
Dataflow 작업자 수: 성능 향상을 위해 최적의 Dataflow 작업자가 필요합니다. 자동 확장을 사용하면 Dataflow는 수행해야 하는 작업량에 따라 작업의 작업자 수를 선택합니다. 하지만 작업자 수는 CPU, 사용 중인 IP 주소, 표준 영구 디스크의 할당량에 따라 제한됩니다. 할당량 한도에 도달하면 Dataflow UI에 경고 아이콘이 표시됩니다. 이러한 경우 진행 속도가 느려지지만 작업은 완료됩니다. 가져올 데이터 양이 많으면 자동 확장으로 인해 Spanner에 과부하가 발생하여 오류가 발생할 수 있습니다.
Spanner의 기존 부하: 가져오기 작업을 실행하면 Spanner 인스턴스에 CPU 부하가 크게 증가합니다. 인스턴스에 이미 상당한 기존 부하가 있다면 작업 실행 속도가 더 느려집니다.
Spanner 컴퓨팅 용량: 인스턴스의 CPU 사용률이 65%를 초과하면 작업 실행 속도가 더 느려집니다.
가져오기 성능을 높일 수 있도록 작업자 조정
Spanner 가져오기 작업을 시작할 때 성능이 향상되도록 Dataflow 작업자를 최적의 값으로 설정해야 합니다. 작업자가 너무 많으면 Spanner에 과부하가 발생하고 작업자가 너무 적으면 가져오기 성능이 저하됩니다.
최대 작업자 수는 데이터 크기에 따라 크게 달라지지만 총 Spanner CPU 사용률은 70~90%여야 합니다. 이렇게 하면 Spanner 효율성과 오류 없는 작업 완료 간의 균형을 잘 잡을 수 있습니다.
대부분의 스키마 및 시나리오에서 이러한 사용률 목표를 달성하려면 Spanner 노드 수의 4~6배에 해당하는 최대 작업자 vCPU 수를 사용하는 것이 좋습니다.
예를 들어 n1-standard-2 작업자를 사용하는 10노드 Spanner 인스턴스의 경우 최대 작업자 수를 25로 설정하여 vCPU 50개를 제공합니다.