개요
Dataproc 영구 기록 서버(PHS)는 활성 또는 삭제된 Dataproc 클러스터에서 실행되는 작업의 작업 기록을 볼 수 있는 웹 인터페이스를 제공합니다. Dataproc 이미지 버전 1.5 이상에서 제공되고 단일 노드 Dataproc 클러스터에서 실행됩니다. 다음 파일 및 데이터에 대한 웹 인터페이스를 제공합니다.
맵리듀스 및 Spark 작업 기록 파일
Flink 작업 기록 파일(Flink 작업을 실행하기 위해 Dataproc 클러스터를 만들려면 Dataproc 선택적 Flink 구성요소 참조)
YARN 타임라인 서비스 v2로 생성되고 Bigtable 인스턴스에 저장되는 애플리케이션 타임라인 데이터 파일입니다.
YARN 집계 로그
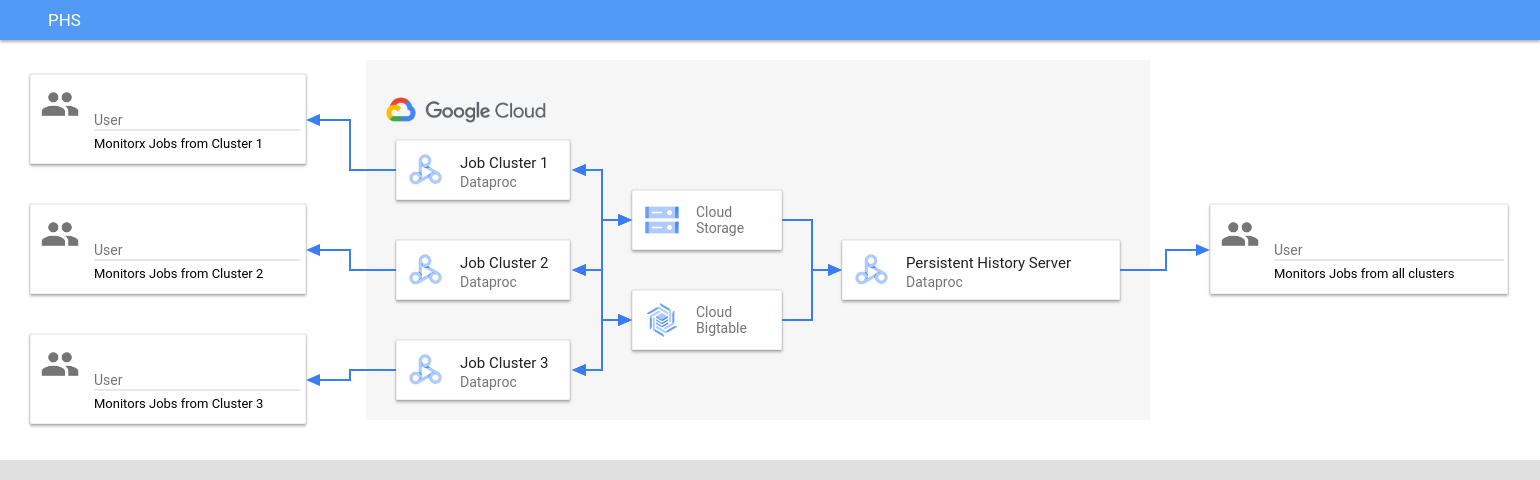
영구 기록 서버가 Dataproc 작업 클러스터의 전체 기간 동안 Cloud Storage에 기록된 Spark 및 맵리듀스 작업 기록 파일, Flink 작업 기록 파일, YARN 로그 파일에 액세스하고 표시합니다.
제한사항
Dataproc PHS 클러스터를 사용하면 PHS 클러스터가 있는 프로젝트에서 실행된 Dataproc 작업의 작업 기록 파일만 볼 수 있습니다. 또한 PHS 클러스터 이미지 버전과 Dataproc 작업 클러스터 이미지 버전이 일치해야 합니다. 예를 들어 Dataproc 2.0 이미지 버전 PHS 클러스터를 사용하면 PHS 클러스터가 있는 프로젝트에 위치한 Dataproc 2.0 이미지 버전 작업 클러스터에서 실행된 작업의 작업 기록 파일을 볼 수 있습니다.
Dataproc PHS 클러스터 만들기
로컬 터미널 또는 Cloud Shell에서 다음 플래그 및 클러스터 속성과 함께 다음 gcloud dataproc clusters create 명령어를 실행하여 Dataproc 영구 기록 서버 단일 노드 클러스터를 만들 수 있습니다.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME: PHS 클러스터의 이름을 지정합니다.
- PROJECT: PHS 클러스터와 연결할 프로젝트를 지정합니다. 이 프로젝트는 작업을 실행하는 클러스터와 연결된 프로젝트와 동일해야 합니다(Dataproc 작업 클러스터 만들기 참조).
- REGION: PHS 클러스터가 위치할 Compute Engine 리전을 지정합니다.
--single-node: PHS 클러스터는 Dataproc 단일 노드 클러스터입니다.--enable-component-gateway: 이 플래그는 PHS 클러스터에서 구성요소 게이트웨이 웹 인터페이스를 사용 설정합니다.- COMPONENT: 클러스터에 하나 이상의 선택적 구성요소를 설치하려면 이 플래그를 사용합니다. Flink 작업 기록 파일을 보려면 PHS 클러스터에서 Flink HistoryServer 웹 서비스를 실행할
FLINK선택적 구성요소를 지정해야 합니다. - PROPERTIES: 클러스터 속성을 한 개 이상 지정합니다.
필요한 경우 --image-version 플래그를 추가하여 PHS 클러스터 이미지 버전을 지정합니다. PHS 이미지 버전이 Dataproc 작업 클러스터의 이미지 버전과 일치해야 합니다. 제한사항을 참고하세요.
참고:
- 이 섹션의 속성 값 예시에서는 '*' 와일드 카드 문자를 사용하여 PHS가 여러 작업 클러스터에 작성된 지정된 버킷의 여러 디렉터리와 일치하도록 허용합니다(와일드 카드 효율성 고려사항 참조하세요).
- 다음 예시에는 가독성을 위해 별도의
--properties플래그가 표시되어 있습니다.gcloud dataproc clusters create를 사용하여 Compute Engine 클러스터에서 Dataproc 클러스터를 만들 때 권장되는 방법은--properties플래그 하나를 사용하여 쉼표로 구분된 속성 목록을 지정하는 것입니다(클러스터 속성 형식 지정 참조).
속성
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: PHS가 작업 클러스터에서 작성된 YARN 로그에 액세스하는 Cloud Storage 위치를 지정하려면 이 속성을 추가합니다.spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: 영구 Spark 작업 기록을 사용 설정하려면 이 속성을 추가합니다. 이 속성은 PHS가 작업 클러스터에서 기록된 Spark 작업 기록 로그에 액세스하는 위치를 지정합니다.Dataproc 2.0+ 클러스터에서는 PHS Spark 기록 로그를 사용 설정하기 위해 다음 두 가지 속성도 설정해야 합니다(Spark 기록 서버 구성 옵션 참조).
spark.history.custom.executor.log.url값은 영구 기록 서버에서 설정되는 변수에 대한 {{PLACEHOLDERS}}가 포함된 리터럴 값입니다. 이러한 변수는 사용자가 설정하지 않으며, 표시된 대로 속성 값을 전달합니다.--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: 영구 맵리듀스 작업 기록을 사용 설정하려면 이 속성을 추가합니다. 이 속성은 PHS가 작업 클러스터에서 작성한 맵리듀스 작업 기록 로그에 액세스하는 Cloud Storage 위치를 지정합니다.dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: Yarn 타임라인 서비스 v2를 구성한 후 PHS 클러스터를 사용하여 YARN 애플리케이션 타임라인 서비스 V2 및 Tez 웹 인터페이스에서 타임라인 데이터를 보려면 이 속성을 추가합니다(구성요소 게이트웨이 웹 인터페이스 참조).flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: 쉼표로 구분된 디렉터리 목록을 모니터링하도록 FlinkHistoryServer를 구성하려면 이 속성을 사용합니다.
속성 예시:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Dataproc 작업 클러스터 만들기
로컬 터미널 또는 Cloud Shell에서 다음 명령어를 실행하여 작업을 실행하고 작업 기록 파일을 영구 기록 서버(PHS)에 기록하는 Dataproc 작업 클러스터를 만들 수 있습니다.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME: 작업 클러스터의 이름을 지정합니다.
- PROJECT: 작업 클러스터와 연결된 프로젝트를 지정합니다.
- REGION: 작업 클러스터가 위치할 Compute Engine 리전을 지정합니다.
--enable-component-gateway: 이 플래그는 작업 클러스터에서 구성요소 게이트웨이 웹 인터페이스를 사용 설정합니다.- COMPONENT: 클러스터에 하나 이상의 선택적 구성요소를 설치하려면 이 플래그를 사용합니다. 클러스터에서 Flink 작업을 실행할
FLINK선택적 구성요소를 지정합니다. PROPERTIES: PHS와 관련된 기본값 이외의 Cloud Storage 위치와 기타 작업 클러스터 속성을 설정하려면 다음 클러스터 속성 중 하나 이상을 추가합니다.
참고:
- 이 섹션의 속성 값 예시에서는 '*' 와일드 카드 문자를 사용하여 PHS가 여러 작업 클러스터에 작성된 지정된 버킷의 여러 디렉터리와 일치하도록 허용합니다(와일드 카드 효율성 고려사항 참조하세요).
- 다음 예시에는 가독성을 위해 별도의
--properties플래그가 표시되어 있습니다.gcloud dataproc clusters create를 사용하여 Compute Engine 클러스터에서 Dataproc 클러스터를 만들 때 권장되는 방법은--properties플래그 하나를 사용하여 쉼표로 구분된 속성 목록을 지정하는 것입니다(클러스터 속성 형식 지정 참조).
속성
yarn:yarn.nodemanager.remote-app-log-dir: 기본적으로 집계된 YARN 로그가 Dataproc 작업에서 사용 설정되고 클러스터 임시 버킷에 기록됩니다. 영구 기록 서버에서 액세스할 수 있도록 클러스터에서 집계 로그를 기록하는 다른 Cloud Storage 위치를 지정하려면 이 속성을 추가합니다.--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectory및spark:spark.eventLog.dir: 기본적으로 Spark 작업 기록 파일은/spark-job-history디렉터리의 클러스터temp bucket에 저장됩니다. 이러한 속성을 추가하여 해당 파일에 대해 다른 Cloud Storage 위치를 지정할 수 있습니다. 두 속성이 모두 사용된 경우 동일한 버킷의 디렉터리를 가리켜야 합니다.--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-dir및mapred:mapreduce.jobhistory.intermediate-done-dir: 기본적으로 맵리듀스 작업 기록 파일은/mapreduce-job-history/done및/mapreduce-job-history/intermediate-done디렉터리의 클러스터temp bucket에 저장됩니다. 중간mapreduce.jobhistory.intermediate-done-dir위치는 임시 스토리지이고, 중간 파일은 맵리듀스 작업이 완료될 때mapreduce.jobhistory.done-dir위치로 이동합니다. 이러한 속성을 추가하여 해당 파일에 대해 다른 Cloud Storage 위치를 지정할 수 있습니다. 두 속성이 모두 사용된 경우 동일한 버킷의 디렉터리를 가리켜야 합니다.--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type및spark:spark.history.fs.gs.outputstream.sync.min.interval.ms: 작업 클러스터가 Cloud Storage로 데이터를 전송하는 방법의 기본 동작을 변경하려면 이러한 Cloud Storage 커넥터 속성을 추가합니다. 기본spark:spark.history.fs.gs.outputstream.type은BASIC이고, 작업 완료 후 데이터를 Cloud Storage로 전송합니다. 이 설정을FLUSHABLE_COMPOSITE로 변경하여 작업이 실행되는 동안 정기적으로 Cloud Storage에 데이터를 복사하도록 플러시 동작을 변경할 수 있습니다.--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
Cloud Storage로 데이터가 전송되는 빈도를 제어하는 기본spark:spark.history.fs.gs.outputstream.sync.min.interval.ms는5000ms이고, 다른ms시간 간격으로 변경할 수 있습니다.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=intervalms
참고: 이러한 속성을 설정하려면 Dataproc 작업 클러스터 이미지 버전이 Cloud Storage 커넥터 버전 2.2.0 이상을 사용해야 합니다. Dataproc 이미지 버전 목록 페이지에서 이미지 버전에 설치된 커넥터 버전을 확인할 수 있습니다.dataproc:yarn.atsv2.bigtable.instance: Yarn 타임라인 서비스 v2를 구성한 후 PHS 클러스터 YARN 애플리케이션 타임라인 서비스 V2 및 Tez 웹 인터페이스에서 볼 수 있도록 YARN 타임라인 데이터를 지정된 Bigtable 인스턴스에 기록하려면 이 속성을 추가합니다. 참고: Bigtable 인스턴스가 없으면 클러스터 만들기가 실패합니다.--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: Flink JobManager는 보관처리된 작업 정보를 파일 시스템 디렉터리에 업로드하여 완료된 Flink 작업을 보관처리합니다. 이 속성을 사용하여flink-conf.yaml의 보관 파일 디렉터리를 설정합니다.--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
Spark 일괄 워크로드에 PHS 사용
Spark 일괄 워크로드에 대해 서버리스 Dataproc에 영구 기록 서버를 사용하려면 다음 안내를 따르세요.
Spark 일괄 워크로드를 제출할 때 PHS 클러스터를 선택하거나 지정합니다.
Google Kubernetes Engine에서 Dataproc에 PHS 사용
GKE 기반 Dataproc에 영구 기록 서버를 사용하려면 다음 안내를 따르세요.
GKE 가상 클러스터에 Dataproc를 만들 때 PHS 클러스터를 선택하거나 지정합니다.
구성요소 게이트웨이 웹 인터페이스
Google Cloud 콘솔의 Dataproc 클러스터 페이지에서 PHS 클러스터 이름을 클릭하여 클러스터 세부정보 페이지를 엽니다. 웹 인터페이스 탭에서 구성요소 게이트웨이 링크를 선택하여 PHS 클러스터에서 실행되는 웹 인터페이스를 엽니다.

Spark 기록 서버 웹 인터페이스
다음 스크린샷은 작업 클러스터의 spark.history.fs.logDirectory 및 spark:spark.eventLog.dir를 설정한 후 job-cluster-1 및 job-cluster-2에서 실행되는 Spark 작업에 대한 링크를 보여주는 Spark기록 서버 웹 인터페이스를 보여주며 PHS 클러스터의 spark.history.fs.logDirectory 위치는 다음과 같습니다.
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |

앱 이름 검색
검색창에 앱 이름을 입력하여 Spark 기록 서버 웹 인터페이스에서 앱 이름으로 작업을 나열할 수 있습니다. 앱 이름은 다음 방법 중 하나로 설정될 수 있습니다(우선순위별 나열).
- Spark 컨텍스트를 만들 때 애플리케이션 코드 내에서 설정
- 작업이 제출될 때 spark.app.name 속성에서 설정
- Dataproc에서 작업의 전체 REST 리소스 이름으로 설정(
projects/project-id/regions/region/jobs/job-id)
검색창에 앱 또는 리소스 이름을 입력하여 작업을 찾고 나열할 수 있습니다.

이벤트 로그
Spark 검색 기록 웹 인터페이스는 클릭하여 Spark 이벤트 로그를 다운로드할 수 있는 이벤트 로그 버튼을 제공합니다. 이러한 로그는 Spark 애플리케이션의 수명 주기를 검사하는 데 유용합니다.
Spark 작업
Spark 애플리케이션은 여러 작업으로 분류되고 작업은 다시 여러 단계로 세분화됩니다. 각 스테이지는 실행자 노드(작업자)에서 실행되는 여러 태스크를 포함할 수 있습니다.

웹 인터페이스에서 Spark 앱 ID를 클릭하여 애플리케이션 내의 이벤트 타임라인 및 작업 요약을 제공하는 Spark 작업 페이지를 엽니다.

작업을 클릭하여 방향성 비순환 그래프(DAG)와 작업 단계 요약을 포함한 작업 세부정보 페이지를 엽니다.
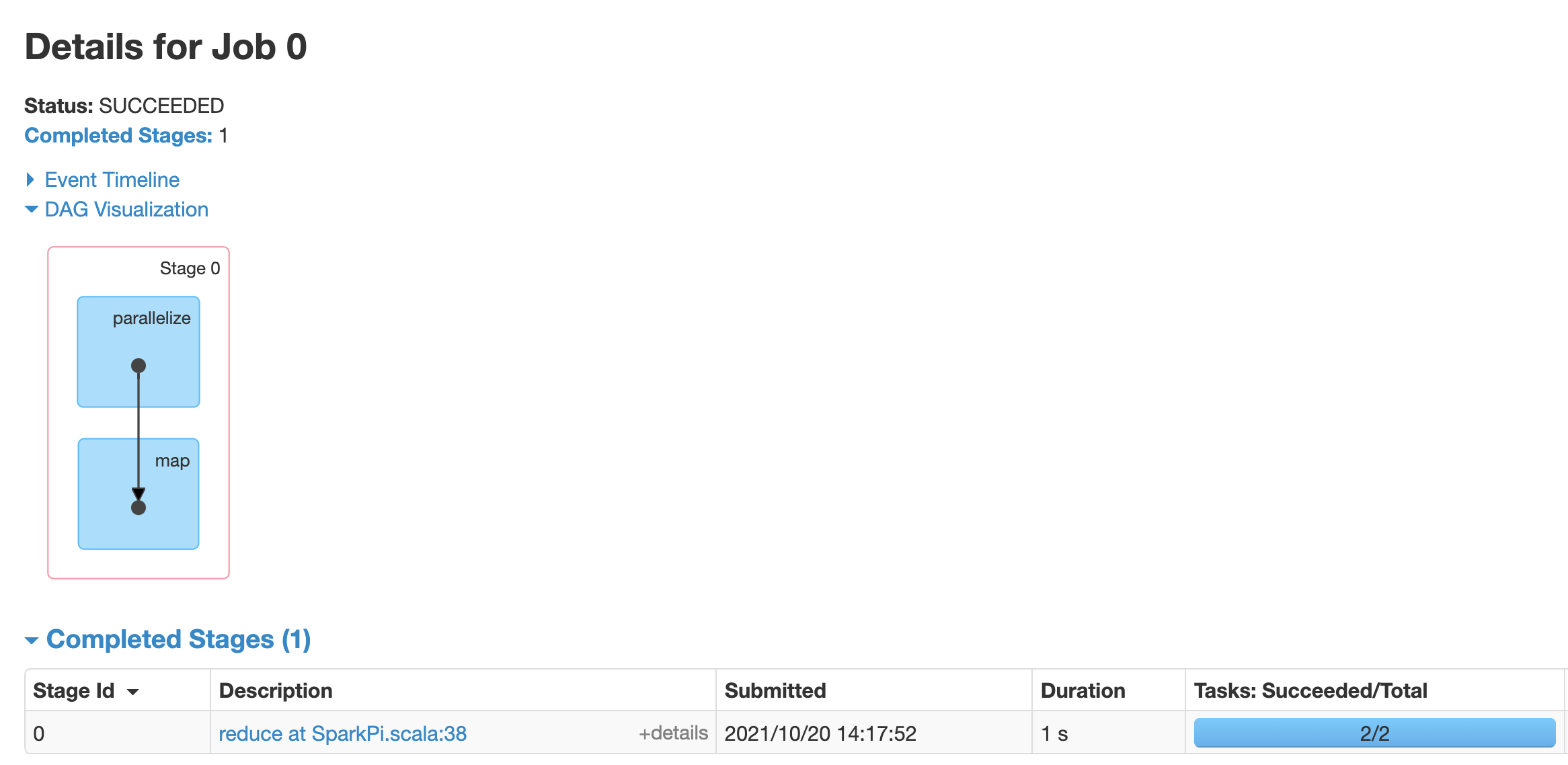
단계를 클릭하거나 단계 탭을 사용하여 단계 세부정보 페이지를 여는 단계를 선택합니다.

단계 세부정보에는 DAG 시각화, 이벤트 타임라인, 단계 내의 태스크 측정항목이 포함됩니다. 이 페이지에서 스트랭글된 태스크, 스케줄러 지연, 메모리 부족 오류와 관련된 문제를 해결할 수 있습니다. DAG 시각화 장치는 단계가 파생된 코드 줄을 보여주는데, 이를 통해 문제를 코드로 추적하는 데 도움이 됩니다.
Spark 애플리케이션의 드라이버 및 실행자 노드에 대한 자세한 내용을 보려면 실행자 탭을 클릭하세요.

이 페이지의 중요한 정보에는 코어 수 및 각 실행자에서 실행된 태스크 수가 포함됩니다.
Tez 웹 인터페이스
Tez는 Dataproc에서 Hive 및 Pig를 위한 기본 실행 엔진입니다. Dataproc 작업 클러스터에서 Hive 작업을 제출하면 Tez 애플리케이션이 실행됩니다(Dataproc에서 Apache Hive 사용 참조).
PHS 및 Dataproc 작업 클러스터를 만들 때 Yarn 타임라인 서비스 v2를 구성하고 dataproc:yarn.atsv2.bigtable.instance 속성을 설정한 경우 PHS 서버에서 실행되는 Tez 웹 인터페이스에서 검색 및 표시할 수 있도록 YARN이 생성된 Hive 및 Pig 작업 타임라인 데이터를 지정된 Bigtable 인스턴스에 기록합니다.

YARN 애플리케이션 타임라인 V2 웹 인터페이스
PHS 및 Dataproc 작업 클러스터를 만들 때 Yarn 타임라인 서비스 v2를 구성하고 dataproc:yarn.atsv2.bigtable.instance 속성을 설정한 경우 PHS 서버에서 실행되는 YARN 애플리케이션 타임라인 서비스 웹 인터페이스에서 검색 및 표시할 수 있도록 YARN이 생성된 작업 타임라인 데이터를 지정된 Bigtable 인스턴스에 기록합니다. Dataproc 작업은 웹 인터페이스에서 흐름 활동 탭에 나열됩니다.

Yarn 타임라인 서비스 v2 구성
Yarn 타임라인 서비스 v2를 구성하려면 Bigtable 인스턴스를 설정하고, 필요한 경우 다음과 같이 서비스 계정 역할을 확인합니다.
필요한 경우 서비스 계정 역할을 확인합니다. Dataproc 클러스터 VM에서 사용되는 기본 VM 서비스 계정은 YARN 타임라인 서비스에 대해 Bigtable 인스턴스를 만들고 구성하는 데 필요한 권한을 갖고 있습니다. 커스텀 VM 서비스 계정으로 작업 또는 PHS 클러스터를 만드는 경우 계정에 Bigtable
Administrator또는Bigtable User역할이 있어야 합니다.
필요한 테이블 스키마
YARN 타임라인 서비스 v2에 대한 Dataproc PHS 지원을 위해서는 Bigtable 인스턴스에 생성된 특정 스키마가 필요합니다. Bigtable 인스턴스를 가리키도록 dataproc:yarn.atsv2.bigtable.instance 속성을 설정하여 작업 클러스터 또는 PHS 클러스터를 만들 때 Dataproc가 필요한 스키마를 만듭니다.
다음은 필요한 Bigtable 인스턴스 스키마입니다.
| 테이블 | column family |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Bigtable 가비지 컬렉션
ATSv2 테이블에 대해 수명 기반의 Bigtable 가비지 컬렉션을 구성할 수 있습니다.
cbt를 설치합니다(
.cbrtc file만들기 포함).ATSv2 수명 기반의 가비지 컬렉션 정책을 만듭니다.
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
참고:
NUMBER_OF_DAYS: 최대 일 수는 30d입니다.