Dataplex est une data fabric qui unifie les données distribuées et automatise la gestion et la gouvernance des données.
Dataplex vous permet d'effectuer les opérations suivantes:
- Créez un maillage de données spécifique à un domaine à partir des données stockées dans plusieurs projets Google Cloud, sans avoir à déplacer les données.
- d'assurer l'homogénéité de la gouvernance et de la surveillance des données à l'aide d'un seul ensemble d'autorisations ;
- Découvrez et sélectionnez les métadonnées réparties entre plusieurs silos à l'aide des fonctionnalités de catalogage. Pour en savoir plus, consultez la présentation du catalogue Dataplex.
- Interrogez les métadonnées de façon sécurisée à l'aide de BigQuery et d'outils Open Source. comme SparkSQL, Presto et HiveQL.
- Exécuter des tâches liées à la qualité des données et à la gestion du cycle de vie des données, y compris sans serveur Spark.
- Explorez des données à l'aide d'environnements Spark sans serveur et entièrement gérés grâce à des aux notebooks et aux requêtes SparkSQL.
Pourquoi utiliser Dataplex ?
Les entreprises disposent de données réparties entre les lacs et les entrepôts de données, magasins de données. Dataplex vous permet d'effectuer les opérations suivantes:
- Découvrir des données
- Sélectionner des données
- Unifier les données sans les déplacer
- Organisez les données en fonction des besoins de votre entreprise
- Gérer, surveiller et gouverner les données de manière centralisée
Dataplex vous permet de standardiser et d'unifier les métadonnées, les règles de sécurité, la gouvernance, la classification et la gestion du cycle de vie des données pour ces données distribuées.
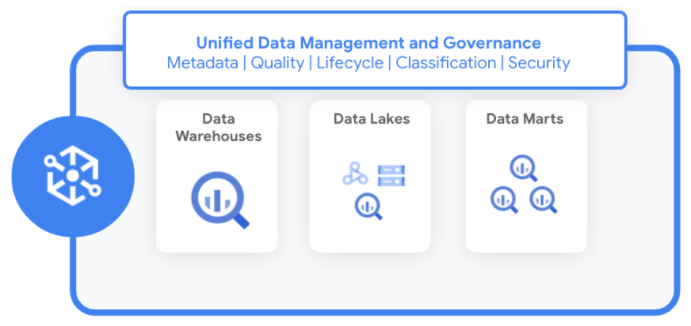
Fonctionnement de Dataplex
Dataplex gère les données d'une manière qui ne nécessite pas de les déplacer ni de les dupliquer. Lorsque vous identifiez de nouvelles sources de données, Dataplex collecte les métadonnées des données structurées et non structurées à l'aide de la des contrôles qualité des données pour améliorer l'intégrité.
Dataplex enregistre automatiquement toutes les métadonnées dans une métastore. Vous pouvez accéder aux données et aux métadonnées à l'aide de divers services et outils, y compris les suivants :
- aux services Google Cloud tels que BigQuery, Dataproc Metastore, Data Catalog.
- Des outils Open Source, tels qu'Apache Spark et Presto.
Terminologie
Dataplex élimine les systèmes de stockage de données sous-jacents, à l'aide des constructions suivantes:
Lac: construction logique représentant un domaine de données ou une unité commerciale. Pour Par exemple, pour organiser les données en fonction de l'utilisation d'un groupe, vous pouvez configurer un lac pour chaque (Commerce, Ventes, Finances, etc.).
Zone: sous-domaine au sein d'un lac, utile pour classer les données par les éléments suivants:
- Étape: par exemple, la page de destination, l'analyse de données brutes et organisées, ainsi que les données sélectionnées la science.
- Utilisation: contrat de données, par exemple.
- Restrictions: par exemple, les contrôles de sécurité et les niveaux d'accès des utilisateurs.
Les zones sont de deux types: brutes et organisées.
Zone brute: contient les données dans leur format brut et non soumises à une vérification stricte du type.
Zone de données organisées: contient les données nettoyées, formatées et prêtes à être utilisées. analyse. Les données sont en colonnes, partitionnées avec Hive et stockées dans Parquet. Avro, fichiers Orc ou tables BigQuery. Les données subissent la vérification du type, par exemple, pour interdire l'utilisation de fichiers CSV, sont moins performantes pour l'accès SQL.
Élément: correspond aux données stockées dans Cloud Storage ou BigQuery. Vous pouvez mapper des données stockées dans des projets Google Cloud distincts en tant qu'assets dans une seule zone.
Entité: représente les métadonnées des données structurées et semi-structurées. (table) et des données non structurées (ensemble de fichiers).
Cas d'utilisation courants
Cette section décrit les cas d'utilisation courants de Dataplex.
Maillage de données centré sur le domaine
Avec ce type de maillage de données, les données sont organisées en plusieurs domaines au sein d'un entreprise, par exemple "Ventes", "Clients" et "Produits". Propriété des données peuvent être décentralisées. Vous pouvez vous abonner aux données de différents domaines. Pour les data scientists et les analystes de données peuvent extraire des informations de différents domaines atteindre des objectifs d'entreprise tels que le machine learning et l'informatique décisionnelle.
Dans le schéma suivant, les domaines sont représentés par Dataplex et appartenant à des producteurs de données distincts. Les producteurs de données propres à la création, la curation et le contrôle des accès dans leurs domaines. Les consommateurs de données peuvent ensuite demander un accès aux lacs (domaines) ou aux zones (sous-domaines) pour leur analyse.
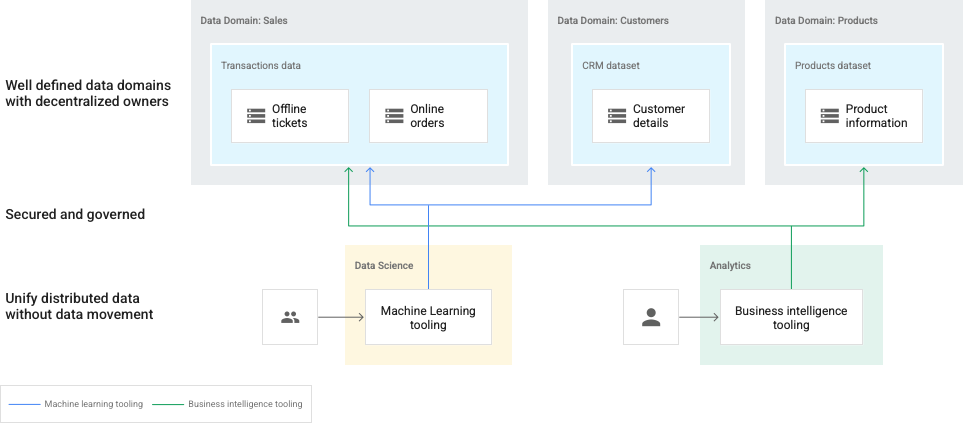
Dans ce cas, les responsables des données doivent conserver une vue globale de l'ensemble du paysage des données.
Ce schéma comprend les éléments suivants:
- Dataplex : maillage de plusieurs domaines de données.
- Domaine: lacs pour les ventes, les clients et les données produit.
- Zone dans un domaine: pour des équipes individuelles ou pour fournir des données gérées contrats.
- Éléments: données stockées dans un bucket Cloud Storage ou un Ensemble de données BigQuery, qui peut exister dans un bucket Google Cloud distinct à partir de votre maillage Dataplex.
Vous pouvez prolonger ce scénario en décomposant les données d'une zone en données brutes et des calques organisés. Vous pouvez y parvenir en créant des zones pour chaque la permutation d'un domaine et de données brutes ou organisées:
- Ventes brutes
- Ventes sélectionnées
- Clients bruts
- Sélection de clients
- Produits bruts
- Produits sélectionnés
Hiérarchisation des données en fonction de l'aptitude
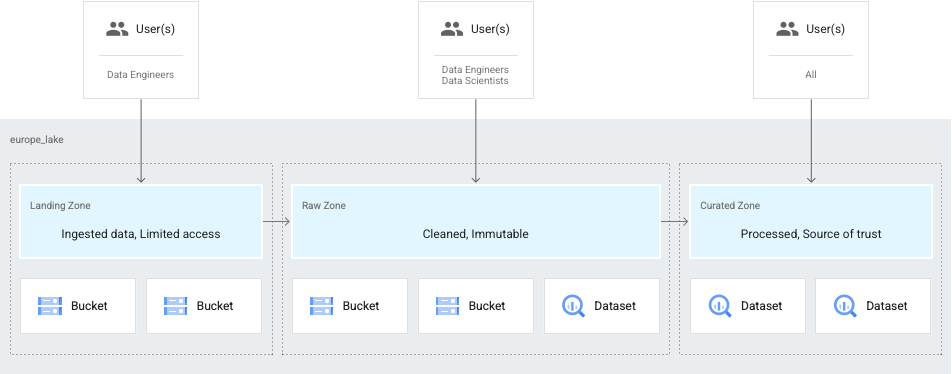
Autre cas d'utilisation courant : lorsque vos données ne sont accessibles qu'aux ingénieurs de données, et sont ensuite affinées et mises à la disposition des data scientists et des analystes. Dans dans ce cas, vous pouvez configurer un lac avec les éléments suivants:
- Zone brute pour les données auxquelles les ingénieurs peuvent accéder.
- Zone sélectionnée pour les données disponibles pour les data scientists et les analystes.
Étape suivante
- Premiers pas avec Dataplex
- Créer un maillage de données
- Créer un lac de données
- Découvrir les fonctionnalités du catalogue dans Dataplex