Cloud Composer 1 | Cloud Composer 2 | Cloud Composer 3
Ce tutoriel explique comment utiliser Cloud Composer pour créer un Graphe orienté acyclique (DAG) pour Apache Airflow qui exécute un job de décompte de mots Apache Hadoop sur Dataproc cluster.
Objectifs
- Accéder à votre environnement Cloud Composer et utiliser la Interface utilisateur Airflow.
- Créer et afficher des variables d'environnement Airflow
- Créer et exécuter un DAG comprenant les tâches suivantes :
- Crée un cluster Dataproc.
- Exécute une Apache Hadoop le job de comptage de mots sur le cluster.
- Génère les résultats du décompte de mots dans un bucket Cloud Storage.
- Supprime le cluster.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- Cloud Composer
- Dataproc
- Cloud Storage
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
Assurez-vous que les API suivantes sont activées dans votre projet :
Console
Enable the Dataproc, Cloud Storage APIs.
gcloud
Enable the Dataproc, Cloud Storage APIs:
gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com Dans votre projet, Créer un bucket Cloud Storage de n'importe quelle classe de stockage et région pour stocker les résultats de l'instance Hadoop le job de décompte de mots.
Notez le chemin d'accès au bucket que vous avez créé, par exemple
gs://example-bucketVous allez définir une variable Airflow pour ce chemin et l'utiliser dans l'exemple de DAG plus tard dans ce tutoriel.Créez un environnement Cloud Composer avec des valeurs par défaut paramètres. Attendez la fin de la création de l'environnement. Une fois l'opération terminée, une coche verte s'affiche à gauche du nom de l'environnement.
Notez la région dans laquelle vous avez créé votre environnement, par exemple
us-centralVous allez définir une variable Airflow pour cette région et l'utiliser dans l'exemple de DAG pour exécuter un cluster Dataproc dans la même région.
Définir les variables Airflow
Définir les variables Airflow que nous utiliserons plus loin dans l'exemple de DAG. Par exemple, vous pouvez définir des variables Airflow dans l'interface utilisateur d'Airflow.
| Variable Airflow | Valeur |
|---|---|
gcp_project
|
L'ID du projet
que vous utilisez pour ce tutoriel, par exemple example-project. |
gcs_bucket
|
Le bucket URI Cloud Storage que vous avez créé pour ce tutoriel
comme gs://example-bucket |
gce_region
|
Région dans laquelle vous avez créé votre environnement, par exemple us-central1.
Il s'agit de la région dans laquelle votre cluster Dataproc
est créé. |
Afficher l'exemple de workflow
Un DAG Airflow est un ensemble de tâches organisées que vous souhaitez programmer
et exécuter. Les DAG sont définis dans des fichiers Python standards. Le code présenté dans
hadoop_tutorial.py est le code du workflow.
Opérateurs
Pour orchestrer les trois tâches de l'exemple de workflow, le DAG importe les les trois opérateurs Airflow suivants:
DataprocClusterCreateOperator: crée un cluster Dataproc.DataProcHadoopOperator: envoie une tâche Hadoop de décompte de mots et écrit les résultats dans un bucket Cloud Storage.DataprocClusterDeleteOperator: supprime le cluster pour éviter tout problème les frais récurrents liés à Compute Engine.
Dépendances
Vous organisez les tâches que vous souhaitez exécuter de manière à refléter les relations et les dépendances. Les tâches de ce DAG sont exécutées de manière séquentielle.
Planification
Ce DAG nommé composer_hadoop_tutorial s'exécute une fois par
jour. Parce que le start_date transmis à default_dag_args est
défini sur yesterday, Cloud Composer planifie le workflow
démarre immédiatement après l'importation du DAG dans le bucket de l'environnement.
Importer le DAG dans le bucket de l'environnement
Cloud Composer stocke les DAG dans le dossier /dags de votre
bucket de l'environnement.
Pour importer le DAG :
Sur votre ordinateur local, enregistrez
hadoop_tutorial.py.Dans la console Google Cloud, accédez à la page Environnements.
Dans la liste des environnements, dans la colonne DAGs folder (Dossier des DAG) de votre cliquez sur le lien DAG.
Cliquez sur Importer des fichiers.
Sélectionnez
hadoop_tutorial.pysur votre machine locale, puis cliquez sur Ouvrir.
Cloud Composer ajoute le DAG à Airflow et le planifie automatiquement. Les modifications sont appliquées au DAG après 3 à 5 minutes.
Explorer les exécutions de DAG
Afficher l'état des tâches
Lorsque vous importez votre fichier DAG dans le dossier dags/ de Cloud Storage,
Cloud Composer analyse le fichier. Une fois la procédure terminée, le nom du workflow apparaît dans la liste des DAG et le workflow est mis en file d'attente pour être exécuté immédiatement.
Pour connaître l'état des tâches, accédez à l'interface Web Airflow, puis cliquez sur DAGs (DAG) dans la barre d'outils.

Pour ouvrir la page de détails des DAG, cliquez sur
composer_hadoop_tutorial. Ce comprend une représentation graphique des tâches les dépendances.
Pour connaître l'état de chaque tâche, cliquez sur Graph View (Vue graphique), puis sur le graphique de chaque tâche.
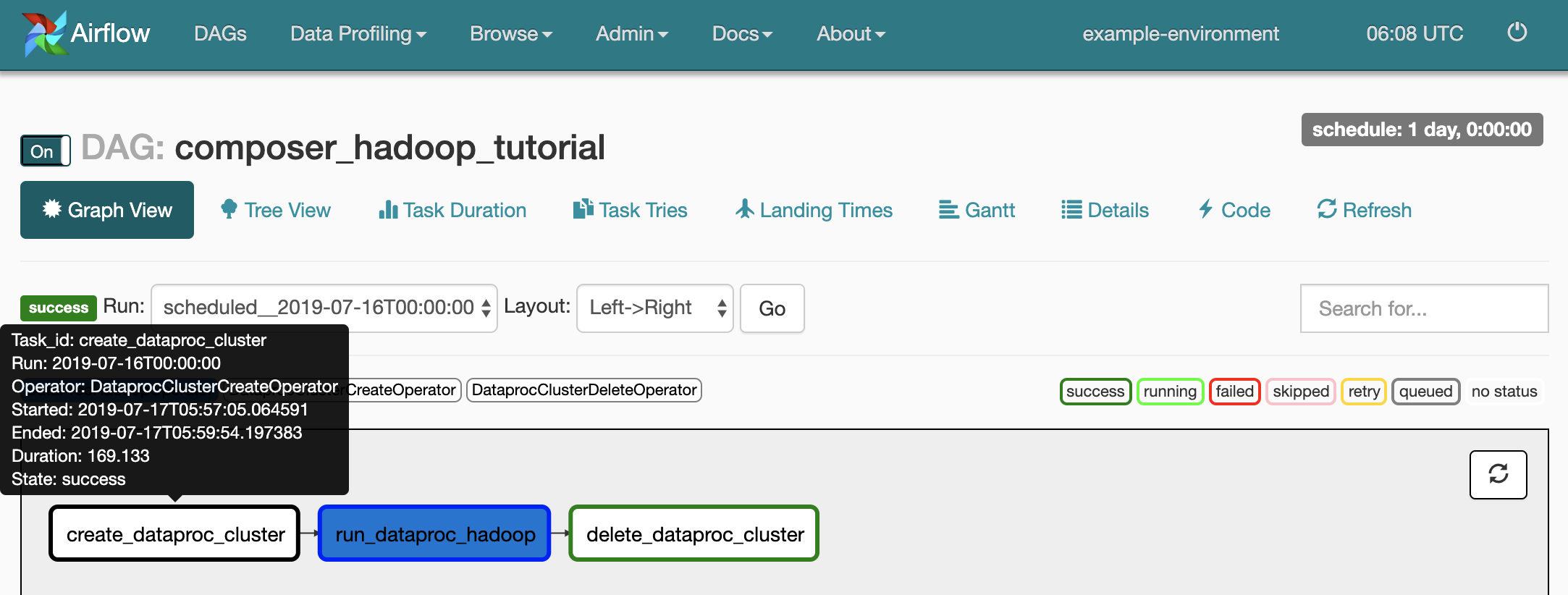
Mettre à nouveau le workflow en file d'attente
Pour exécuter de nouveau le workflow à partir de la vue graphique, procédez comme suit :
- Dans la vue graphique de l'interface utilisateur Airflow, cliquez sur le graphique
create_dataproc_cluster. - Pour réinitialiser les trois tâches, cliquez sur Clear (Effacer), puis sur OK pour confirmer.
- Cliquez de nouveau sur
create_dataproc_clusterdans la vue graphique. - Pour remettre le workflow en file d'attente, cliquez sur Run (Exécuter).
Afficher les résultats des tâches
Vous pouvez également vérifier l'état et les résultats de composer_hadoop_tutorial.
en accédant aux pages suivantes de la console Google Cloud:
Clusters Dataproc: pour surveiller la création des clusters et de suppression. Notez que le cluster créé par le workflow est éphémère : il n'existe que pour la durée du workflow et est supprimé dans le cadre de sa dernière tâche.
Jobs Dataproc: pour afficher ou surveiller Apache Hadoop "wordcount". Cliquez sur l'ID de job pour afficher la sortie du journal associée au job.
Navigateur Cloud Storage: pour afficher les résultats du décompte de mots dans le dossier
wordcountdans le bucket Cloud Storage que vous avez créé pour ce tutoriel.
Nettoyage
Supprimez les ressources utilisées dans ce tutoriel:
Supprimez l'environnement Cloud Composer, y compris supprimer manuellement le bucket de l'environnement.
Supprimez le bucket Cloud Storage que stocke les résultats du job de décompte de mots Hadoop.