Übersicht: Data Warehouses zu BigQuery migrieren
In diesem Dokument werden die allgemeinen Konzepte erläutert, die für jede Data Warehouse-Technologie gelten. Außerdem wird ein Framework beschrieben, mit dem Sie Ihre Migration zu BigQuery organisieren und strukturieren können.
Terminologie
Bei der Erörterung der Data Warehouse-Migration verwenden wir die folgende Terminologie:
- Anwendungsfall
-
Ein Anwendungsfall umfasst alle Datasets, Datenverarbeitungen sowie die System- und Nutzerinteraktionen, die zur Realisierung eines geschäftlichen Nutzens erforderlich sind, z. B. das Tracking des Umsatzvolumens für ein Produkt über einen längeren Zeitraum. Bei Data-Warehouse-Vorgängen besteht ein Anwendungsfall häufig aus folgenden Elementen:
- Datenpipelines, die Rohdaten aus verschiedenen Datenquellen wie der CRM-Datenbank (Customer Relationship Management) aufnehmen.
- Den im Data Warehouse gespeicherten Daten.
- Skripts und Verfahren zum Ändern, Weiterverarbeiten und Analysieren der Daten.
- Einer Geschäftsanwendung, die die Daten liest oder mit ihnen interagiert.
- Arbeitslast
- Eine Reihe von Anwendungsfällen, die miteinander verknüpft sind und gemeinsame Abhängigkeiten haben. Ein Anwendungsfall kann beispielsweise die folgenden Beziehungen und Abhängigkeiten haben:
- Die Einkaufsberichterstattung kann eigenständig erfolgen und hilfreich sein, um die Ausgaben zu verstehen und Rabatte anzufordern.
- Die Verkaufsberichterstattung kann eigenständig erfolgen und hilfreich für die Planung von Marketingkampagnen sein.
- Die Gewinn-und-Verlustrechnung ist jedoch sowohl von den Einkäufen als auch von den Verkäufen abhängig und hilfreich, um den Unternehmenswert zu bestimmen.
- Geschäftsanwendung
- Ein System, mit dem Endnutzer interagieren, z. B. ein visueller Bericht oder ein Dashboard. Eine Geschäftsanwendung kann auch eine Betriebsdatenpipeline oder ein Feedback-Loop sein. Wenn beispielsweise die Änderungen der Produktpreise berechnet oder vorhergesagt wurden, lassen sich die neuen Produktpreise über eine Betriebsdatenpipeline in einer Transaktionsdatenbank aktualisieren.
- Vorgelagerter Prozess
- Die Quellsysteme und Datenpipelines, über die Daten in das Data Warehouse geladen werden.
- Nachgelagerter Prozess
- Die Skripts, Verfahren und Geschäftsanwendungen, mit denen die Daten im Data Warehouse verarbeitet, abgefragt und visualisiert werden.
- Auslagerungsmigration
- Eine Migrationsstrategie, bei der der Anwendungsfall entweder so schnell wie möglich für den Endnutzer in der neuen Umgebung bereitgestellt werden soll oder bei der die zusätzlichen Kapazitäten genutzt werden sollen, die in der neuen Umgebung zur Verfügung stehen. Anwendungsfälle können mit folgenden Verfahren ausgelagert werden:
- Kopieren und anschließendes Synchronisieren des Schemas und der Daten aus dem Legacy-Data-Warehouse
- Migrieren der nachgelagerten Skripts, Verfahren und Geschäftsanwendungen
Die Auslagerung der Migration kann zur Erhöhung der Komplexität und des Aufwands bei der Migration von Datenpipelines führen.
- Vollständige Migration
- Ein Migrationskonzept ähnlich der Auslagerungsmigration. Statt jedoch das Schema und die Daten zu kopieren und anschließend zu synchronisieren, konfigurieren Sie hier die Migration so, dass die Daten von den vorgelagerten Quellsystemen direkt in das neue Cloud Data Warehouse übernommen werden. Die für den Anwendungsfall erforderlichen Datenpipelines werden hier also ebenfalls migriert.
- Enterprise Data Warehouse (EDW)
- Ein Data Warehouse, das nicht nur aus einer analytischen Datenbank besteht, sondern auch mehrere zentrale Analysekomponenten und -verfahren enthält. Dazu gehören Datenpipelines, Abfragen und Geschäftsanwendungen, die zur Bewältigung der Arbeitslast des Unternehmens erforderlich sind.
- Cloud Data Warehouse (CDW)
- Ein Data Warehouse mit den gleichen Eigenschaften wie ein EDW, das jedoch mit einem vollständig verwalteten Dienst in der Cloud ausgeführt wird – in diesem Fall mit BigQuery.
- Datenpipeline
- Ein Prozess, der Datensysteme über eine Reihe von Funktionen und Aufgaben für verschiedene Arten der Datentransformation miteinander verbindet. Ausführliche Informationen dazu finden Sie unter Was ist eine Datenpipeline? in dieser Reihe.
Warum zu BigQuery migrieren?
In den vergangenen Jahrzehnten haben Unternehmen sich die Technik des Data Warehousing angeeignet und genutzt. Dabei wurden immer mehr deskriptive Analysen auf große gespeicherte Datenmengen angewendet, um Einblick in die Abläufe des Kerngeschäfts zu bekommen. Die herkömmliche Business Intelligence (BI), bei der Abfragen, Berichterstellung sowie analytische Onlineverarbeitung im Mittelpunkt stehen, war in der Vergangenheit möglicherweise oft das Zünglein an der Waage, das über Erfolg oder Misserfolg eines Unternehmens entschied. Heute reicht BI allein jedoch nicht mehr aus.
Inzwischen müssen Unternehmen nicht nur vergangene Ereignisse mithilfe von deskriptiven Analysen nachvollziehbar machen, sondern sie benötigen darüber hinaus Analysen zu Prognosezwecken. Häufig wird dazu maschinelles Lernen (ML) eingesetzt, um Datenmuster zu extrahieren und Wahrscheinlichkeitsaussagen über die Zukunft zu treffen. Das eigentliche Ziel besteht aber darin, präskriptive Analysen zu entwickeln, in denen Erfahrungen aus der Vergangenheit mit Prognosen für die Zukunft verknüpft werden, um eine automatisierte Orientierungshilfe für Aktionen in der Gegenwart zur Verfügung zu stellen.
Traditionell werden Rohdaten für Data Warehouses aus verschiedenen Quellen erfasst. Dabei handelt es sich häufig um Systeme zur Online-Transaktionsverarbeitung (Online Transactional Processing, OLTP). Danach wird in Batches eine Teilmenge der Daten extrahiert, anhand eines definierten Schemas angepasst und in das Data Warehouse geladen. Da in herkömmlichen Data Warehouses Daten als Teilmengen in Batches erfasst und nach strikten Schemas gespeichert werden, sind die Daten nicht für Echtzeitanalysen oder für die Beantwortung spontaner Abfragen geeignet. Die Entwicklung von BigQuery durch Google war zum Teil auch eine Folge dieser damit verbundenen Einschränkungen.
Innovative Konzepte werden häufig durch die Größe und Komplexität der IT-Abteilung behindert, die für die Implementierung und Instandhaltung dieser traditionellen Data Warehouses notwendig sind. Es kann oft Jahre dauern und beträchtliche Investitionen nach sich ziehen, eine skalierbare, hochverfügbare und sichere Data-Warehouse-Architektur aufzubauen. BigQuery bietet eine ausgereifte SaaS-Technologie (Software as a Service), die für serverlose Data-Warehouse-Vorgänge verwendet werden kann. Damit können Sie sich auf den Ausbau Ihres Kerngeschäfts konzentrieren und Google Cloud die Infrastrukturverwaltung sowie die Plattformentwicklung überlassen.
BigQuery ermöglicht skalierbaren, flexiblen und kostengünstigen Zugriff auf die strukturierte Speicherung, Verarbeitung und Analyse von Daten. Diese Eigenschaften sind von zentraler Bedeutung, wenn Ihr Datenvolumen exponentiell zunimmt. In diesem Fall stehen Ihnen damit Speicher- und Verarbeitungsressourcen je nach Bedarf zur Verfügung und Sie können Ihre Daten zur Wertschöpfung nutzen. BigQuery bietet Unternehmen, die erst mit Big-Data-Analysen und maschinellem Lernen starten und die die potenzielle Komplexität lokaler Big-Data-Systeme vermeiden möchten, darüber hinaus die Möglichkeit, verwaltete Dienste zu testen und nur für die tatsächlich in Anspruch genommenen Dienste zu bezahlen ("Pay as you go").
Big Data ermöglicht es Ihnen, Antworten auf zuvor schwer lösbare Probleme zu finden, mithilfe von maschinellem Lernen neu entstehende Datenmuster zu ermitteln und neue Hypothesen zu prüfen. Im Ergebnis erhalten Sie damit einen zeitnahen Einblick in die Leistungsfähigkeit Ihres Unternehmens und können durch Änderung von Prozessen Ihre Ergebnisse verbessern. Wie später noch erläutert wird, verbessert sich das Erlebnis des Endnutzers häufig durch relevante Einblicke, die aus Big-Data-Analysen abgeleitet werden können.
Was und wie migriert wird: der Migrationsumfang
Die Durchführung einer Migration kann ein komplexes und langwieriges Unterfangen sein. Wir empfehlen daher, sich an einem gewissen Rahmen zu orientieren, durch den die Migrationsarbeit in Phasen organisiert und strukturiert wird:
- Vorbereiten und Analysieren: Bereiten Sie sich auf die Migration mit der Analyse der Arbeitslast und des Anwendungsfalls vor.
- Planen: Priorisieren Sie Anwendungsfälle, definieren Sie Erfolgsindikatoren und planen Sie Ihre Migration.
- Ausführen: Wiederholen Sie die Schritte für die Migration, von der Bewertung bis zur Validierung.
Vorbereiten und Analysieren
In der ersten Phase liegt der Schwerpunkt auf Vorbereitung und Analyse. Es geht dabei darum, sich selbst und allen Beteiligten frühzeitig die Gelegenheit zu bieten, die vorhandenen Anwendungsfälle zu untersuchen und mögliche erste Probleme zu benennen. Außerdem müssen Sie in dieser Phase eine erste Analyse des erwarteten Nutzens erstellen. Dazu gehören Aspekte wie die Steigerung der Leistung (z. B. Verbesserung der Nebenläufigkeit) und die Senkung der Gesamtbetriebskosten (Total cost of ownership, TCO). Diese Phase ist entscheidend für die Wertschöpfung durch die Migration.
Ein Data Warehouse unterstützt in der Regel eine Vielzahl von Anwendungsfällen und wird von einer großen Zahl von Beteiligten genutzt, von Datenanalysten bis zu den Entscheidungsträgern des Unternehmens. Wir empfehlen daher, Vertreter dieser Gruppen einzubeziehen, um ein Verständnis für die vorhandenen Anwendungsfälle zu entwickeln und abwägen zu können, ob die Leistung dieser Anwendungsfälle gut ist und ob die Beteiligten neue Anwendungsfälle planen.
Der Prozess der Analysephase umfasst die folgenden Aufgaben:
- Untersuchen Sie die Vorzüge von BigQuery und nehmen Sie einen Vergleich zu Ihrem Legacy-Data-Warehouse vor.
- Führen Sie eine erste TCO-Analyse durch.
- Stellen Sie fest, welche Anwendungsfälle von der Migration betroffen sind.
- Erfassen Sie die Merkmale der zugrunde liegenden Datasets und Datenpipelines, die Sie migrieren möchten, um Abhängigkeiten zu identifizieren.
Entwerfen Sie einen Fragebogen, um Informationen von Experten, Endnutzern und sonstigen Beteiligten zusammenzutragen. So erhalten Sie einen Einblick in die Anwendungsfälle. Der Fragebogen sollte folgende Informationen enthalten:
- Was ist das Ziel des Anwendungsfalls? Was ist der Nutzen für das Unternehmen?
- Welche nichtfunktionalen Anforderungen bestehen? Datenaktualität, gleichzeitige Verwendung usw.
- Ist der Anwendungsfall Teil einer größeren Arbeitslast? Ist er von anderen Anwendungsfällen abhängig?
- Welche Datasets, Tabellen und Schemas liegen dem Anwendungsfall zugrunde?
- Was wissen Sie über die Datenpipelines, über die diese Datasets gespeist werden?
- Welche BI-Tools, Berichte und Dashboards werden derzeit verwendet?
- Welche aktuellen technischen Voraussetzungen bestehen rund um betriebliche Anforderungen, Leistung, Authentifizierung und Netzwerkbandbreite?
Das folgende Diagramm bietet einen groben Überblick über die Legacy-Architektur vor der Migration. Darin werden der Katalog der verfügbaren Datenquellen, Legacy-Datenpipelines, Legacy-Betriebspipelines und Feedback-Loops sowie Legacy-BI-Berichte und -Dashboards veranschaulicht, auf die die Endnutzer zugreifen.

Planen
In der Planungsphase wird die Eingabe aus der Vorbereitungs- und Erkennungsphase herangezogen, bewertet und dann zur Planung der Migration verwendet. Diese Phase kann in die folgenden Aufgaben unterteilt werden:
Anwendungsfälle katalogisieren und priorisieren
Wir empfehlen Ihnen, den Migrationsprozess in Iterationen aufzuteilen. Katalogisieren Sie sowohl vorhandene als auch neue Anwendungsfälle und weisen Sie ihnen jeweils eine Priorität zu. Ausführliche Informationen dazu finden Sie in den Abschnitten Mithilfe eines iterativen Ansatzes migrieren und Anwendungsfälle priorisieren in diesem Dokument.
Erfolgsindikatoren definieren
Es ist hilfreich, vor der Migration eindeutige Erfolgsindikatoren wie z. B. Leistungskennzahlen (Key Performance Indicators, KPIs) zu definieren. Mit diesen Indikatoren können Sie den Erfolg der Migration bei jeder Iteration bewerten und der Migrationsprozess in den späteren Iterationen verbessern.
Endzustand definieren
Bei komplexen Migrationen ist es nicht immer direkt erkennbar, ob die Migration eines bestimmten Anwendungsfalls abgeschlossen ist. Daher ist eine formale Definition des von Ihnen gewünschten Endzustands empfehlenswert. Diese Definition sollte so allgemein gehalten sein, dass sie auf alle zu migrierenden Anwendungsfälle angewendet werden kann. Sie sollte als Mindestkriterium gelten, das erfüllt sein muss, damit ein Anwendungsfall als vollständig migriert betrachtet werden kann. Diese Definition enthält in der Regel Prüfpunkte, mit denen sich sicherstellen lässt, dass der Anwendungsfall eingebunden, getestet und dokumentiert wurde.
Proof of Concept (POC), einen kurzfristigen Zustand und einen idealen Endzustand festlegen und vorschlagen
Nachdem Sie Ihre Anwendungsfälle priorisiert haben, können Sie sie über die gesamte Dauer der Migration betrachten. Die Migration des ersten Anwendungsfalls kann als Proof of Concept (PoC) dienen, um das ursprüngliche Migrationskonzept zu validieren. Überlegen Sie, was in den ersten Wochen bis Monaten als kurzfristiger Zustand erreichbar ist. Wie wirken sich Ihre Migrationspläne auf die Nutzer aus? Wird es eine hybride Lösung geben oder können Sie zuerst die gesamte Arbeitslast für eine Untergruppe von Nutzern migrieren?
Zeitabschätzungen und Kostenvoranschläge erstellen
Für ein erfolgreiches Migrationsprojekt ist es wichtig, die jeweilige Dauer realistisch einzuschätzen. Wenden Sie sich dazu an alle relevanten Beteiligten, um deren Verfügbarkeit zu besprechen und zu vereinbaren, in welchem Umfang sie sich am gesamten Projekt beteiligen werden. So lassen sich die Arbeitskosten genauer einschätzen. Informationen zum Schätzen der Kosten für die voraussichtlich benötigten Cloud-Ressourcen finden Sie in der BigQuery-Dokumentation unter Speicher- und Abfragekosten schätzen und Einführung in die Kontrolle der BigQuery-Kosten.
Einen Migrationspartner identifizieren und mit diesem zusammenarbeiten
In der BigQuery-Dokumentation werden viele Tools und Ressourcen beschrieben, die Sie für die Migration verwenden können. Die selbstständige Durchführung einer großen, komplexen Migration kann jedoch schwierig sein, wenn Sie keine Vorkenntnisse haben oder in Ihrem Unternehmen nicht das erforderliche technische Fachwissen vorhanden ist. Wir empfehlen Ihnen daher, von Beginn an einen Migrationspartner zu identifizieren und einzubinden. Weitere Informationen finden Sie in unseren Programmen für globale Partner und Beratungsdienstleistungen.
Mithilfe eines iterativen Ansatzes migrieren
Bei der Migration eines umfangreichen Data-Warehouse-Prozesses in die Cloud empfiehlt sich ein iterativer Ansatz. Daher empfehlen wir Ihnen, die Umstellung auf BigQuery in Iterationen vorzunehmen. Die Aufteilung der Migration in Iterationen erleichtert den Gesamtprozess, verringert das Risiko und bietet Gelegenheiten, nach jeder Iteration Erfahrungswerte einzubringen und Verbesserungen einfließen zu lassen.
Eine Iteration besteht aus allen Arbeiten, die für eine Auslagerungsmigration oder eine vollständige Migration eines oder mehrerer zugehöriger Anwendungsfälle innerhalb eines bestimmten Zeitraums erforderlich sind. Eine Iteration entspricht einem Sprintzyklus im agilen Konzept, der aus einer oder mehreren User Storys besteht.
Aus Gründen der Einfachheit und zur leichten Nachverfolgung können Sie einen einzelnen Anwendungsfall mit einer oder mehreren User Storys verknüpfen. Nehmen Sie beispielsweise die folgende User Story: "Als Preisanalytiker möchte ich die Veränderungen der Produktpreise im Laufe des letzten Jahres analysieren, um künftige Preise kalkulieren zu können."
Der entsprechende Anwendungsfall dazu könnte so aussehen:
- Aufnahme der Daten aus einer Transaktionsdatenbank, in der Produkte und Preise gespeichert sind
- Umwandlung der Daten in eine einzelne Zeitachse pro Produkt und Berechnung fehlender Werte
- Speichern der Ergebnisse in einer oder mehreren Tabellen im Data Warehouse
- Bereitstellung der Ergebnisse über ein Python-Notebook (die Geschäftsanwendung)
Der geschäftliche Nutzen dieses Anwendungsfalls besteht in der Unterstützung der Preisanalyse.
Wie in den meisten Anwendungsfällen werden auch hier voraussichtlich mehrere User Storys unterstützt.
Auf einen ausgelagerten Anwendungsfall folgt wahrscheinlich eine weitere Iteration, um den Anwendungsfall vollständig zu migrieren. Andernfalls besteht möglicherweise weiterhin eine Abhängigkeit vom vorhandenen Legacy-Data-Warehouse, da die Daten von dort kopiert werden. Die anschließende vollständige Migration ist das Delta zwischen der Auslagerung und einer vollständigen Migration, der keine Auslagerungsmigration vorausgeht. Dabei geht es also um die Migration der Datenpipeline(s) für das Extrahieren, Umwandeln und Laden der Daten in das Data Warehouse.
Anwendungsfälle priorisieren
Wo Sie die Migration beginnen und beenden, hängt von Ihren individuellen Geschäftsanforderungen ab. Die Entscheidung über die Reihenfolge, in der Anwendungsfälle migriert werden, ist wichtig, denn der frühe Erfolg ist maßgeblich, damit der Umstieg auf die Cloud fortgeführt werden kann. Ein frühzeitiges Auftreten von Fehlern kann eine erhebliche Beeinträchtigung der gesamten Migrationsanstrengungen zur Folge haben. Sie können zwar die Vorteile von Google Cloud und BigQuery nutzen, aber die Verarbeitung aller Datasets und Datenpipelines, die in Ihrem Legacy-Data-Warehouse für verschiedene Anwendungsfälle erstellt oder verwaltet wurden, kann kompliziert und zeitaufwendig sein.
Obwohl es keine einheitliche Lösung gibt, können Sie bei der Bewertung Ihrer lokalen Anwendungsfälle und Geschäftsanwendungen auf Best Practices zurückgreifen. Diese Art der Vorausplanung kann den Migrationsprozess vereinfachen und die gesamte Umstellung auf BigQuery reibungsloser gestalten.
In den folgenden Abschnitten werden mögliche Ansätze zum Priorisieren von Anwendungsfällen erläutert.
Ansatz: Aktuelle Chancen nutzen
Informieren Sie sich über aktuelle Möglichkeiten, die dazu beitragen könnten, den Return on Investment eines bestimmten Anwendungsfalls zu maximieren. Dieser Ansatz ist besonders nützlich, wenn Sie unter Druck stehen und den geschäftlichen Nutzen einer Migration in die Cloud rechtfertigen müssen. Er bietet auch die Möglichkeit zur Erfassung zusätzlicher Datenpunkte, um die Gesamtmigrationskosten besser einschätzen zu können.
Im Folgenden finden Sie einige Beispielfragen, mit denen Sie herausfinden können, welche Anwendungsfälle Priorität haben sollten:
- Besteht der Anwendungsfall aus Datasets oder Datenpipelines, die derzeit durch das Legacy-Data-Warehouse des Unternehmens eingeschränkt sind?
- Erfordert das vorhandene Legacy-Data-Warehouse des Unternehmens eine Aktualisierung der Hardware oder ist davon auszugehen, dass die Hardware erweitert werden muss? In diesem Fall ist es unter Umständen sinnvoll, Anwendungsfälle eher früher als später nach BigQuery auszulagern.
Migrationsmöglichkeiten zu identifizieren kann zum schnellen Erfolg führen, der sowohl den Nutzern als auch dem Unternehmen greifbare, unmittelbare Vorteile bietet.
Ansatz: Analytische Arbeitslasten zuerst migrieren
Migrieren Sie die OLAP-Arbeitslasten (OLAP), bevor Sie die OLTP-Arbeitslasten ((OLTP)) migrieren. Ein Data Warehouse ist häufig der einzige Ort im Unternehmen, an dem alle für die Erstellung einer einzigen globalen Übersicht über die Vorgänge des Unternehmens erforderlichen Daten hinterlegt sind. Daher ist es in Unternehmen üblich, dass über einige Datenpipelines eine Einspeisung in die Transaktionssysteme erfolgt, um den Status zu aktualisieren oder Prozesse auszulösen, z. B. um den Lagerbestand aufzufüllen, wenn dieser für ein Produkt recht gering ist. OLTP-Arbeitslasten sind in der Regel komplexer und haben strengere Betriebsanforderungen und Service Level Agreements (SLAs) als OLAP-Arbeitslasten. Somit ist es normalerweise einfacher, zuerst OLAP-Arbeitslasten zu migrieren.
Ansatz: Nutzererfahrung in den Vordergrund stellen
Identifizieren Sie Möglichkeiten, die Nutzerfreundlichkeit zu verbessern. Migrieren Sie dazu bestimmte Datasets und ermöglichen Sie neue Arten erweiterter Analysen. Eine Möglichkeit, das Nutzererlebnis zu verbessern, sind beispielsweise Echtzeitanalysen. Sie können anspruchsvolle Nutzererlebnisse um einen Echtzeitdatenstrom aufbauen, wenn dieser mit historischen Daten zusammengeführt wird. Beispiel:
- Ein Backoffice-Mitarbeiter, der über eine mobile App auf geringe Lagerbestände aufmerksam gemacht wird.
- Ein Online-Kunde, der von der Information profitieren könnte, dass er die nächste Prämienstufe erreicht, wenn er einen Dollar mehr ausgibt.
- Eine Krankenpflegerin, die auf ihrer Smartwatch über die Vitalfunktionen eines Patienten informiert wird. So kann sie die bestmögliche Vorgehensweise ermitteln, indem sie den Behandlungsverlauf des Patienten auf ihrem Tablet abruft.
Die Nutzererfahrung lässt sich auch durch prognostische und präskriptive Analysen verbessern. Dazu können Sie BigQuery ML, Vertex AI AutoML Tabular oder die vortrainierten Modelle von Google für Bildanalyse, Videoanalyse, Spracherkennung,natürliche Sprache und Übersetzung verwenden. Alternativ können Sie Ihr eigenes trainiertes Modell mithilfe von Vertex AI für Anwendungsfälle bereitstellen, die auf Ihre Geschäftsanforderungen zugeschnitten sind. Dies kann folgende Punkte umfassen:
- Die Empfehlung eines Produkts aufgrund von Markttrends und des Kaufverhaltens der Nutzer
- Prognosen zu Flugverspätungen
- Das Erkennen von betrügerischen Aktivitäten
- Die Kennzeichnung von unangemessenen Inhalten
- Andere innovative Konzepte, mit denen sich Ihre Anwendung von jenen Ihrer Wettbewerber abhebt
Ansatz: Anwendungsfälle mit dem geringsten Risiko bevorzugt abwickeln
Es gibt eine Reihe von Fragen, die der IT-Abteilung dabei helfen können, zu beurteilen, welche Anwendungsfälle das geringste Migrationsrisiko aufweisen und somit für eine frühe Migration infrage kommen. Beispiel:
- Wie wichtig ist dieser Anwendungsfall für das Unternehmen?
- Ist eine große Anzahl von Mitarbeitern oder Kunden auf den Anwendungsfall angewiesen?
- Was ist die Zielumgebung (z. B. Entwicklung oder Produktion) für den Anwendungsfall?
- Wie versteht unser IT-Team den Anwendungsfall?
- Wie viele Abhängigkeiten und Integrationen hat der Anwendungsfall?
- Verfügt unser IT-Team über eine ordnungsgemäße, aktuelle und ausführliche Dokumentation zu dem Anwendungsfall?
- Welche betrieblichen Anforderungen (SLAs) bestehen für den Anwendungsfall?
- Welche gesetzlichen oder behördlichen Complianceanforderungen gibt es für den Anwendungsfall?
- Wie hoch sind die Ausfall- und Latenzzeiten für den Zugriff auf das zugrunde liegende Dataset?
- Gibt es Leiter von Geschäftszweigen, die motiviert und bereit sind, ihren Anwendungsfall frühzeitig zu migrieren?
Das Durchgehen dieser Liste von Fragen kann hilfreich sein, um eine Einstufung der Datasets und Datenpipelines vom niedrigsten zum höchsten Risiko vorzunehmen. Ressourcen mit geringem Risiko sollten zuerst, Ressourcen mit höherem Risiko später migriert werden.
Ausführen
Nachdem Sie Informationen zu Ihren Legacy-Systemen zusammengetragen und eine Prioritätenliste der Anwendungsfälle erstellt haben, können Sie die Anwendungsfälle in Arbeitslasten gruppieren und mit der Migration in Iterationen fortfahren.
Eine Iteration kann aus einem einzelnen Anwendungsfall, einigen separaten Anwendungsfällen oder einer Reihe von Anwendungsfällen bestehen, die zu einer einzelnen Arbeitslast gehören. Welche dieser Optionen Sie für eine Iteration auswählen sollten, hängt von der Interkonnektivität der Anwendungsfälle, den gemeinsamen Abhängigkeiten und den Ressourcen ab, die Ihnen für die Durchführung der Arbeit zur Verfügung stehen.
Eine Migration umfasst in der Regel die folgenden Schritte:
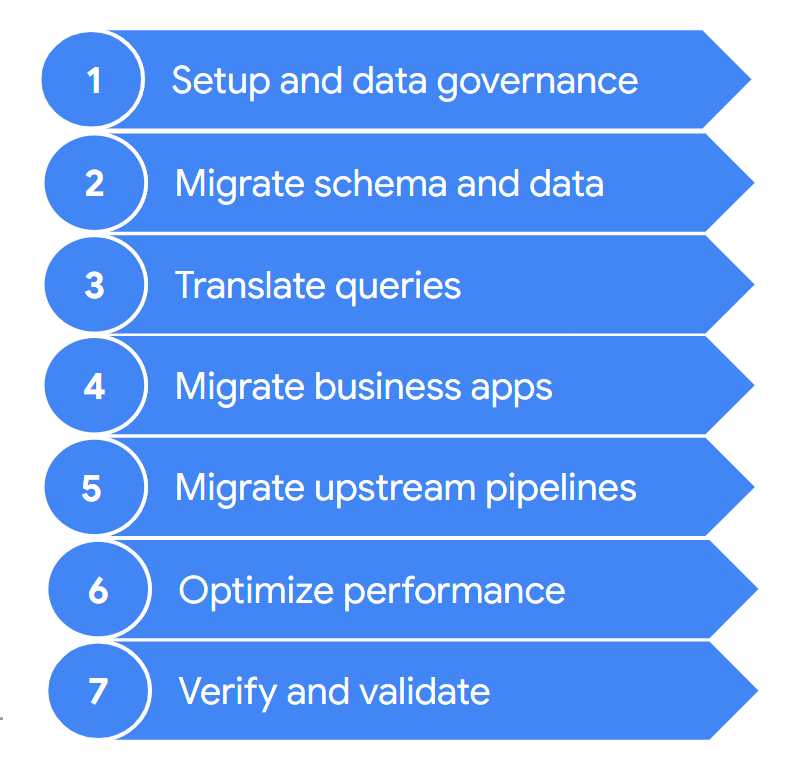
Diese Ebenen werden in den folgenden Abschnitten ausführlicher beschrieben. Möglicherweise müssen Sie nicht alle diese Schritte in jeder Iteration durchlaufen. Beispielsweise können Sie sich in einer Iteration darauf konzentrieren, einige Daten aus Ihrem Legacy-Data-Warehouse nach BigQuery zu kopieren. Im Gegensatz dazu können Sie beispielsweise in einer nachfolgenden Iteration die Aufnahmepipeline der ursprünglichen Datenquelle direkt in BigQuery ändern.
1. Einrichten und Data Governance
Das Einrichten ist die grundlegende Arbeit, die zum Ausführen der Anwendungsfälle in Google Cloud erforderlich ist. Das Einrichten umfasst etwa die Konfiguration der Google Cloud-Projekte, des Netzwerks, der Virtual Private Cloud (VPC) und die Data Governance. Dazu gehört auch ein gutes Verständnis dafür, wo Sie heute stehen – was funktioniert und was nicht. So können Sie die Anforderungen für Ihre Migrationsbemühungen besser verstehen. Sie können das Feature der BigQuery-Migrationsbewertung verwenden, damit es Sie bei diesem Schritt unterstützt.
Die Data Governance ist ein wesentlicher Ansatz zur Verwaltung von Daten während ihres Lebenszyklus, von der Erfassung über die Verwendung bis zur Vernichtung. In Ihrem Data Governance-Programm werden Richtlinien, Verfahren, Verantwortlichkeiten und Kontrollen für die Datenaktivitäten klar festgelegt. Mit diesem Programm wird sichergestellt, dass Informationen so gesammelt, verwaltet, verwendet und weitergegeben werden, dass sowohl die Datenintegrität als auch die Sicherheitsanforderungen Ihres Unternehmens erfüllt sind. Dies trägt außerdem dazu bei, dass Ihre Mitarbeiter die Daten leichter finden und optimal nutzen.
Die Dokumentation zur Data Governance hilft Ihnen, die Data Governance und die Kontrollelemente zu verstehen, die für die Migration Ihres lokalen Data Warehouse zu BigQuery notwendig sind.
2. Schema und Daten migrieren
Das Data-Warehouse-Schema definiert die Struktur Ihrer Daten und die Beziehungen zwischen Ihren Dateneinheiten. Das Schema ist der Kern Ihres Datendesigns und wirkt sich auf viele vor- und nachgelagerte Prozesse aus.
Das Dokument zum Thema Schema und Datenübertragung enthält ausführliche Informationen zum Verschieben Ihrer Daten nach BigQuery sowie Empfehlungen zur Aktualisierung Ihres Schemas, damit Sie die Features von BigQuery optimal nutzen können.
3. Abfragen übersetzen
Verwenden Sie die Batch-SQL-Übersetzung, um Ihren SQL-Code im Bulk zu migrieren, oder die interaktive SQL-Übersetzung, um Ad-hoc-Abfragen zu übersetzen.
Einige ältere Data Warehouses enthalten Erweiterungen des SQL-Standards, mit denen sich Funktionen für ihr Produkt aktivieren lassen. BigQuery unterstützt diese proprietären Erweiterungen nicht. Stattdessen entspricht es dem Standard ANSI/ISO SQL:2011. Dies bedeutet, dass für einige Ihrer Abfragen möglicherweise eine manuelle Refaktorierung erforderlich ist, wenn die SQL-Übersetzer sie nicht interpretieren können.
4. Geschäftsanwendungen migrieren
Geschäftsanwendungen können viele Formen annehmen – von Dashboards über benutzerdefinierte Anwendungen bis zu Betriebsdatenpipelines, über die Feedbackschleifen für Transaktionssysteme bereitgestellt werden.
Weitere Informationen zu den Analyseoptionen bei der Arbeit mit BigQuery finden Sie unter Übersicht über die BigQuery-Analyse. Dieses Thema bietet einen Überblick über die Berichts- und Analysetools, mit denen Sie aussagekräftige Statistiken Ihrer Daten erhalten können.
Im Abschnitt zu Feedback-Loops aus der Dokumentation zu Datenpipelines wird beschrieben, wie Sie eine Datenpipeline nutzen können, um mithilfe eines Feedback-Loops vorgelagerte Systeme zu speisen.
5. Datenpipelines migrieren
In der Dokumentation zu Datenpipelines werden Verfahren, Muster und Technologien für die Migration Ihrer Legacy-Datenpipelines zu Google Cloud beschrieben. Dort wird erläutert, was eine Datenpipeline ist, welche Verfahren und Muster sie nutzen kann und welche Optionen und Technologien für die Migration eines größeren Data Warehouse verfügbar sind.
6. Leistung optimieren
BigQuery verarbeitet Daten effizient bei kleinen Datenmengen sowie Datenmengen im Petabyte-Bereich. Mithilfe von BigQuery sollten Ihre Datenanalysejobs einwandfrei funktionieren, ohne dass Sie Änderungen am neu migrierten Data Warehouse vornehmen müssen. Wenn Sie feststellen, dass die Abfrageleistung unter bestimmten Umständen nicht Ihren Erwartungen entspricht, lesen Sie die Anleitung unter Einführung in die Optimierung der Abfrageleistung.
7. Überprüfen und Validieren
Überprüfen Sie am Ende jeder Iteration, ob die Migration des Anwendungsfalls erfolgreich verlaufen ist. Prüfen Sie dazu folgende Punkte:
- Die Daten und das Schema wurden vollständig migriert.
- Bedenken hinsichtlich der Data Governance wurden vollständig geprüft und ausgeräumt.
- Es wurden Instandhaltungs- und Monitoringverfahren sowie eine Automatisierung eingeführt.
- Abfragen wurden richtig übersetzt.
- Migrierte Datenpipelines funktionieren wie erwartet.
- Geschäftsanwendungen sind richtig konfiguriert, um auf die migrierten Daten und Abfragen zuzugreifen.
Sie können mit dem Datenvalidierungstool beginnen, einem Open Source-Python-Befehlszeilentool, das Daten aus Quell- und Zielumgebungen vergleicht, um sicherzustellen, dass sie übereinstimmen. Es unterstützt mehrere Verbindungstypen zusammen mit einer mehrstufigen Validierungsfunktion.
Wir empfehlen außerdem, die Auswirkungen der Anwendungsfallmigration zu messen, z. B. in Form der Leistungssteigerung, Kostensenkung oder der Eröffnung neuer technischer oder geschäftlicher Möglichkeiten. Dann können Sie den Wert des Return on Investment genauer quantifizieren und diesen mit Ihren Erfolgskriterien für die Iteration vergleichen.
Nachdem die Iteration validiert wurde, können Sie den migrierten Anwendungsfall für die Produktion freigeben und Ihren Nutzern Zugriff auf migrierte Datasets und Geschäftsanwendungen gewähren.
Machen Sie sich abschließend Notizen und dokumentieren Sie die Erfahrungen aus dieser Iteration, damit Sie diese bei der nächsten Iteration einbringen und die Migration beschleunigen können.
Zusammenfassung der Migration
Während der Migration führen Sie sowohl Ihr Legacy-Data-Warehouse als auch BigQuery aus, wie in diesem Dokument beschrieben. Die Referenzarchitektur im folgenden Diagramm zeigt, dass beide Data Warehouses ähnliche Funktionen und Pfade bieten. Beide können Daten aus den Quellsystemen aufnehmen, in die Geschäftsanwendungen eingebunden werden und für den erforderlichen Nutzerzugriff sorgen. Das Diagramm zeigt außerdem, dass Daten von Ihrem Data Warehouse nach BigQuery synchronisiert werden. Dadurch können Anwendungsfälle während der gesamten Dauer der Migration ausgelagert werden.

Wenn Sie eine vollständige Migration von Ihrem Data Warehouse zu BigQuery ausführen, sieht der Endzustand der Migration in etwa so aus:

Nächste Schritte
Mehr über die folgenden Schritte bei der Data Warehouse-Migration erfahren:
- Migrationsbewertung
- Schema- und Datenübertragung
- Datenpipelines
- Batch-SQL-Übersetzung
- Interaktive SQL-Übersetzung
- Datensicherheit und Governance
- Datenvalidierungstool
Außerdem erfahren Sie, wie Sie von bestimmten Data Warehouse-Technologien zu BigQuery wechseln:
- Von Netezza migrieren
- Migration von Oracle
- Von Amazon Redshift migrieren
- Von Teradata migrieren
- Von Snowflake migrieren